关于作者
张帅,网络从业人员,公众号:Flowlet
个人博客:https://flowlet.net/
序言
Linux 连接跟踪子系统(Linux Conntrack)是实现带状态的包过滤与 NAT 功能的基础,一般工作中我们都将 Linux Conntrack 称之为 “CT”。此前也有很多关于 Linux Conntrack 的文章介绍,但这些文章都是基于较老的 kernel 版本进行讲解,内容有点过时了。本文基于 Linux kernel 5.10 LTS 对 Conntrack 的底层运作方式进行详细介绍。
本文翻译自系列文章 Connection tracking (conntrack),原文共分为三篇,笔者将三篇合为一篇进行讲解,本文主要分为以下三个章节:
- 第一部分:CT 系统(CT System’s)概述,详细说明了 CT 系统与 Netfilter 和 Nftables 等其他内核组件的关系。
- 第二部分:CT 系统(CT System’s)底层实现,详细说明了连接跟踪表(conntrack table)、连接查找和连接生命周期管理是如何工作的。
- 第三部分:如何通过 IPtables/Nftables 分析和跟踪连接状态,并通过 ICMP、UDP 和 TCP 等一些常见协议示例进行说明。
前言
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
0. 概览
Conntrack 有什么作用?当 Linux 一旦激活连接跟踪,CT 系统就会检查 IPv4/IPv6 报文及其 payload,以确定哪些报文之间彼此关联。CT 系统并不参与端到端通信,而是透明的执行观测检查。一条连接的端点是本地还是远端都与 CT 系统无关。当端点位于远程主机上时,CT 系统仅在路由或桥接该报文的主机上进行观测。CT 系统维护其所有跟踪的连接实时列表。CT 系统为每个报文提供一个到其连接跟踪实例的引用(指针),在报文经过内核协议栈的时候对报文进行“分类”。其他内核组件可以根据此引用访问该报文所关联的连接跟踪实例并据此做出处理决策。
Conntrack 最主要的应用是 NAT 子系统以及 Iptables 和 Nftables 的带状态包过滤/带状态包检测 (SPI:stateful packet inspection) 模块。CT 系统本身并不修改/操纵报文,因此 CT 系统一般不会主动丢包。在进行报文检查时主要检查报文的 3 层和 4 层信息,因此它能够跟踪 TCP、UDP、ICMP、ICMPv6、SCTP、DCCP 和 GRE 等连接。
CT 系统对“连接”的定义并不局限于面向连接的协议,例如,它将 ICMP echo-request 与 echo-reply (ping) 视为一条“连接”。CT 系统同时提供了一些扩展组件,可以将其连接跟踪能力扩展到应用层,例如,跟踪 FTP、TFTP、IRC、PPTP、SIP 等应用层协议,该能力是实现应用层网关的基础。
1. CT 系统(CT System’s)概述
1.1 模块自动加载
内核的实现细节很大程度上取决于内核的编译构建配置,本文以 Debian 系统为例进行讲解。
围绕 Netfilter 框架并在其之上构建的整个基础设施由大量相互独立的内核模块组成,模块与模块之间具有复杂的依赖关系。其中许多模块通常不需要管理员使用 modprobe 或 insmod 命令显式加载,它们会按需自动加载。为了实现模块按需自动加载,Netfilter 通过调用 auto loader 内核模块提供的 request_module() 函数来实现这一点。当该函数被调用时,它通过执行一个运行 modprobe (kmod) 命令的用户态进程来加载所请求的模块以及该模块所依赖的所有模块。
1.2 nft_ct 模块
CT 系统会按模块自动加载的方式按需加载。一些内核组件需要使用连接跟踪特性,并能够触发 CT 系统模块的自动加载。以 nft_ct 内核模块为例,它是 Nftables 的带状态包过滤模块。该模块为 Nftables 提供基于连接跟踪表达式(CONNTRACK EXPRESSIONS)的报文匹配规则;这些表达式以 ct 关键字作为开头,并且可以根据 ct 的状态(ct state …)来匹配报文。
nft add rule ip filter forward iif eth0 ct state new drop
nft add rule ip filter forward iif eth0 ct state established accept
图 1.1:示例,将基于连接跟踪表达式(CONNTRACK EXPRESSIONS)的 Nftables 规则添加到 forward 链中
第一条 Nftables 规则:匹配在 eth0 接口上收到进行 IPv4 转发的一条新的连接跟踪(ct state new)的第一个报文,比如,TCP SYN 包,该规则将对其进行丢弃。 第二条 Nftables 规则:匹配在 eth0 接口上收到进行 IPv4 转发的已建立连接跟踪(ct state established)的报文,该规则将接收该报文。
在第一次将包含连接跟踪表达式(CONNTRACK EXPRESSIONS)的 Nftables 规则添加到规则集时,会触发 nft_ct 内核模块自动加载。该模块的依赖关系如图 1.2 所示,因此会自动加载一大堆其所依赖的模块,包括代表实际 ct 系统的 nf_conntrack 模块,以及 nf_defrag_ipv4/nf_defrag_ipv6 等其他模块。
nft_ct # Nftables ct expressions and statements
nf_tables
nfnetlink
nf_conntrack # ct system
nf_defrag_ipv4 # IPv4 defragmentation
nf_defrag_ipv6 # IPv6 defragmentation
libcrc32c
图 1.2:nft_ct 内核模块的依赖树
1.3 网络命名空间(Network Namespace)
这些模块加载后并不会导致所有模块立刻被激活。与内核网络协议栈的许多其他部分一样,ct 系统 nf_conntrack 以及 nf_defrag_ipv4/nf_defrag_ipv6 模块在每个网络命名空间内独立执行。
网络命名空间
每个网络命名空间运行完全独立的网络协议栈,每个网络命名空间都有一组自己的网络设备、独立的网络配置和设备状态,例如 IP 地址、路由、邻居表、Netfilter hook 点、Iptables/Nftables rulesets 等,因此,每个网络命名空间都拥有自己独立的网络流量。默认情况下,系统启动后,仅存在名为 “init_net” 的默认网络命名空间,并且所有网络都发生在该网络命名空间内。可以在运行时添加或删除其他网络命名空间,例如 Docker 和 LXC 等容器解决方案使用网络命名空间为每个容器提供隔离的网络资源。
ct 系统被设计为仅在当前网络命名空间中生效。
1.4 Netfilter hook 点
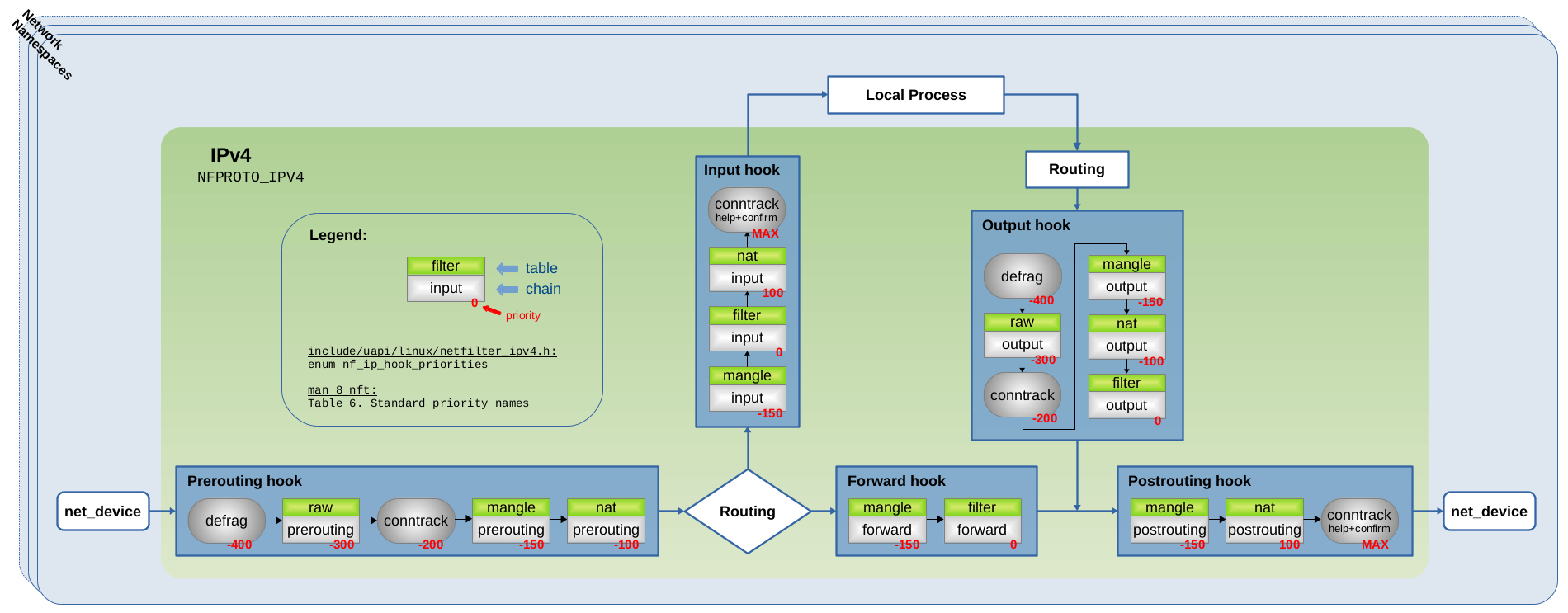
与 Iptables 和 Nftables 一样,ct 系统基于 Netfilter 框架进行构建。ct 系统将能够观测网络报文的钩子函数,注册到 Netfilter hook 点上。Netfilter 数据流图如图 1.3 所示:
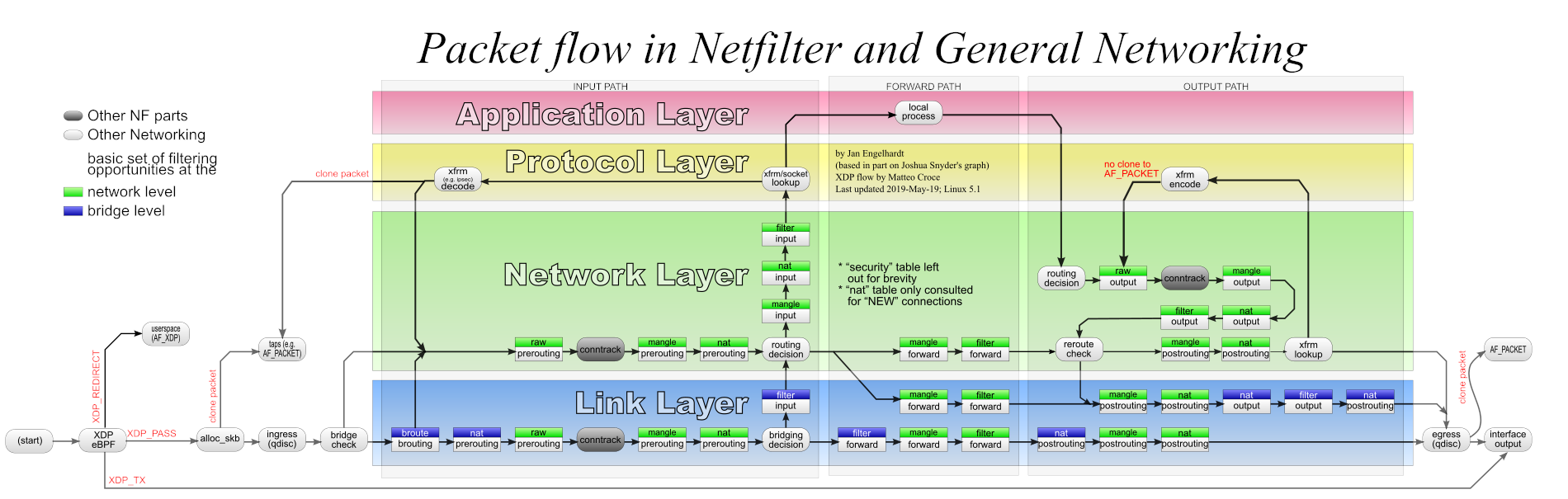
图 1.3:Netfilter 数据流图
图中名为 conntrack 的方块代表 ct 系统的钩子函数。每个独立的网络命名空间都有完全相同的 Netfilter hook 点,如:Prerouting, Input, Forward, Output 和 Postrouting。该 hook 点代表网络命名空间内 ct 系统的启用/禁用开关。因此,ct 系统只能“看到”自己所在网络命名空间上的报文。
1.5 nf_conntrack 模块
当第一条带有连接跟踪表达式(CONNTRACK EXPRESSION)的 Nftables 规则添加到当前网络命名空间的规则集(ruleset)中时,Nftables 代码会触发 nf_conntrack 内核模块被自动加载(如果该模块尚未加载)。随后,Nftables 代码调用 nf_ct_netns_get() 函数,该函数由刚刚加载的 nf_conntrack 内核模块提供(export)。当该函数被调用时,它将 ct 系统的钩子函数注册到当前网络命名空间的 Netfilter hook 点上。
图 1.1 所示的 Nftables 规则指定了 ip 地址族。因此,ct 系统会向图 1.4 所示的 IPv4 Netfilter hook 点注册四个钩子函数。对于 ip6 地址族,ct 系统会向 IPv6 的 Netfilter hook 点注册相同的四个挂钩函数。对于 inet 地址族,ct 系统会同时向 IPv4 和 IPv6 Netfilter hook 点注册其挂钩函数。
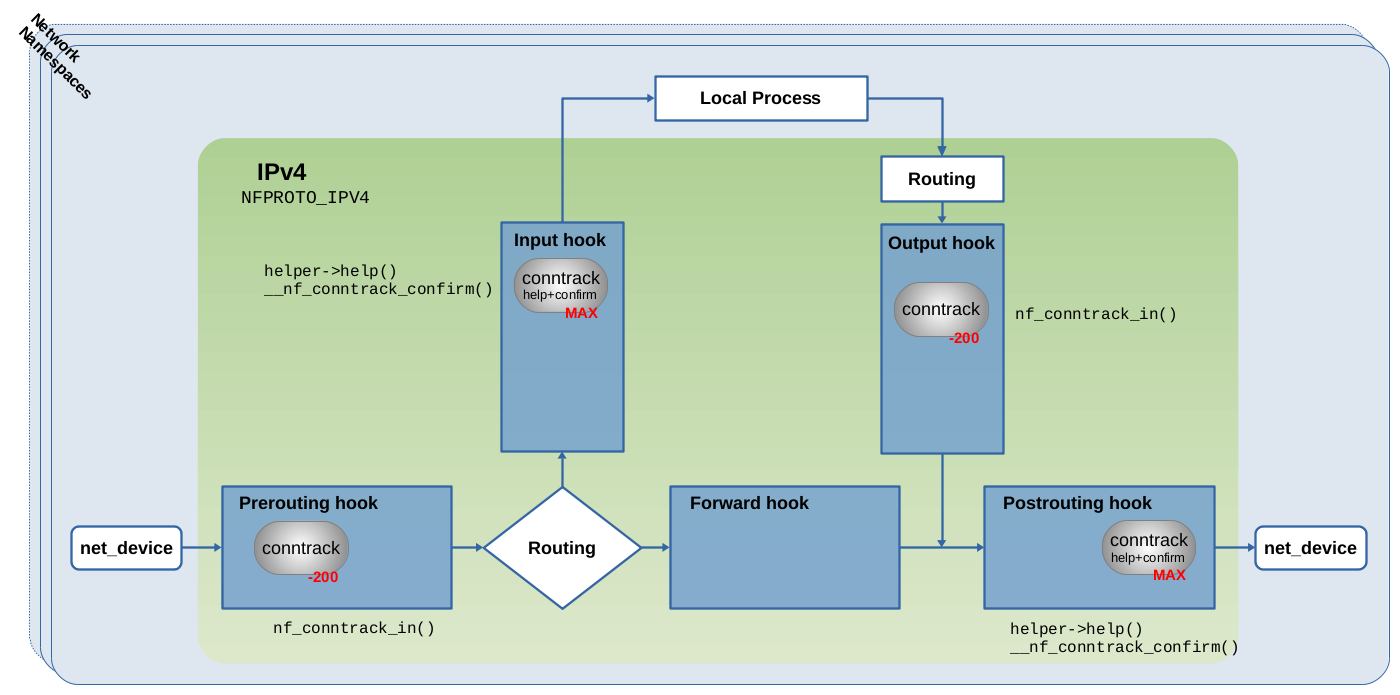
图 1.4:四个 conntrack 钩子函数注册到 Netfilter IPv4 hook 点。具体代码请参阅 net/netfilter/nf_conntrack_proto.c
ct 系统使用 nf_ct_netns_get() 函数是注册钩子函数,通过使用 nf_ct_netns_put() 函数可以取消注册。如果在当前网络命名空间中,同时有几个内核组件都需要使用连接跟踪而调用 nf_ct_netns_get() 函数,nf_ct_netns_get()/nf_ct_netns_put() 通过在内部使用引用计数解决这个问题。
nf_ct_netns_get() 函数仅在第一次被调用时注册 ct 系统的钩子函数,当被连续调用时仅增加引用计数。如果某个内核组件在某个时刻不再需要使用连接跟踪,它通过调用 nf_ct_netns_put() 来减少引用计数。如果引用计数为零,nf_ct_netns_put() 则取消 ct 钩子函数注册。例如,如果当前网络命名空间规则集中包含跟踪表达式(CONNTRACK EXPRESSION)的所有 Nftables 规则被删除,就会发生这种情况。该机制确保 ct 系统只在需要时才被启用。
1.5.1 主要的 ct 钩子函数
以 -200 优先级注册到图 1.4 Prerouting hook 点和 Output hook 点的两个钩子函数基本完全相同。在内部,它们都做差不多同样的事情。它们调用的主要函数是 nf_conntrack_in(),两者之间的主要区别仅在于 hook 点的位置,Prerouting hook 用于处理网络上接收的报文,而 Output hook 用于处理本地主机上产生的输出报文。这两个 hook 可以被认为是 ct 系统的“主要”钩子函数,ct 系统遍历网络数据包的大部分操作都发生在两个钩子函数内部,分析报文并将报文与其连接跟踪关联起来,然后为这些报文提供到连接跟踪实例的引用(指针)。
1.5.2 help + confirm 钩子函数
另外两个钩子函数以 MAX 优先级注册到图 1.4 中的 Input 和 Postrouting hook 点。MAX 表示最高无符号整数,具有此优先级的钩子函数将作为 Netfilter hook 点中的最后一个函数进行遍历,并且在它之后不能注册任何其他钩子函数。
这两个钩子函数并没有在图 1.3 中体现,它们都对遍历的报文执行相同的操作。两者的唯一区别在于它们在 Netfilter hook 点中的位置不同,这确保了所有报文,无论是进入/输出/转发的报文,在遍历完所有其他钩子函数之后,最后都能遍历这两个钩子函数中的其中一个。
在本文中,我将其称为连接跟踪 “help+confirm” 钩子函数。一个是执行 “helper” 代码,这是一项高级功能,仅在某些特定用例中使用。二是 “confirm” 新跟踪的连接,具体代码请参阅 __nf_conntrack_confirm() 函数,后面我们会对其进行详细说明。
在 v5.10.19 内核中 “helper” 和 “confirm” 组合存在于同一钩子函数中。在 v4.19 LTS 内核中,优先级为 300 的 “helper” 钩子函数和优先级为 MAX 的 “confirm” 钩子函数以单独的 ct 钩子函数的形式存在于 Netfilter Input 和 Postrouting hook 点
1.6 nf_defrag_ipv4/6 模块
如图 1.2 所示,nf_conntrack 模块依赖于 nf_defrag_ipv4 和 nf_defrag_ipv6 模块。这两个模块分别负责 IPv4 和 IPv6 报文的分片重组。通常情况下,应该在接收端而不是在中间节点进行分片重组。正常情况下,只有当一条连接的所有报文都能够被识别时,连接跟踪才能正常工作。然而对于分片报文,分片报文并不都包含识别它们所需的必要协议头信息。
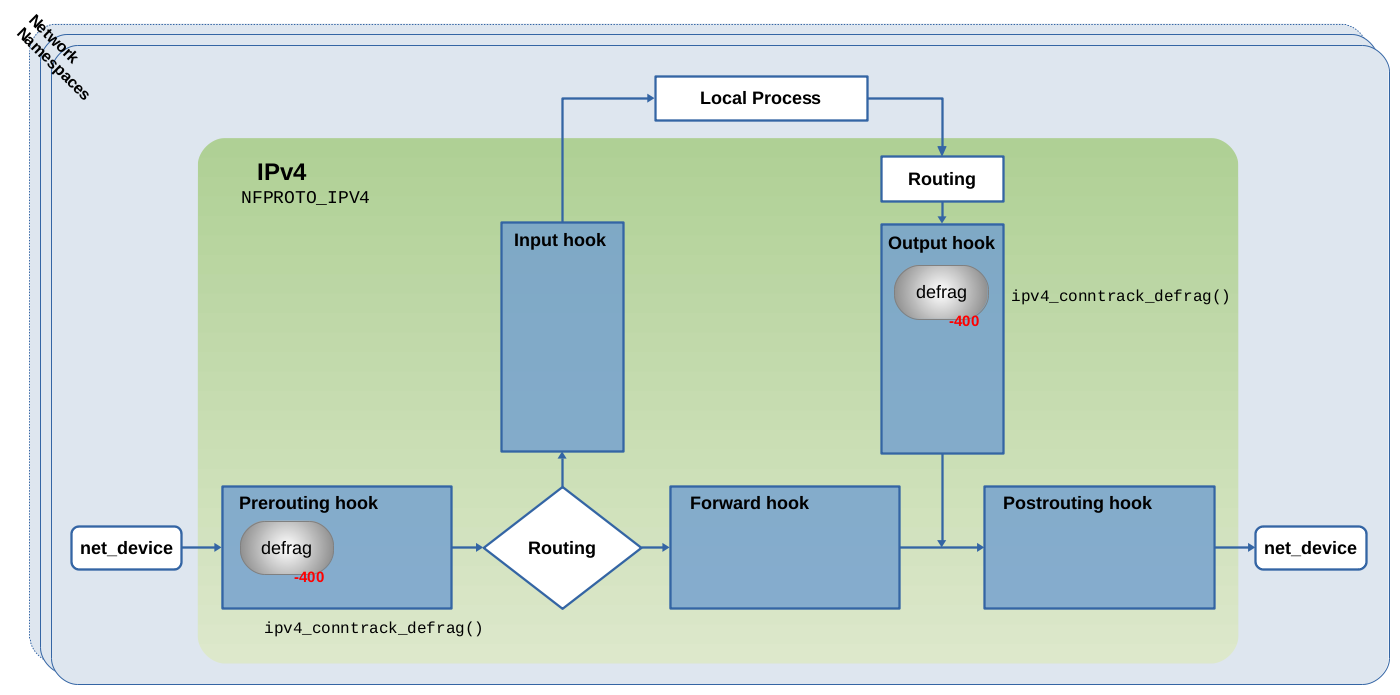
图 1.5:分片重组钩子函数注册到 Netfilter IPv4 hook 点。具体代码请参阅 net/ipv4/netfilter/nf_defrag_ipv4.c
与 ct 系统本身类似,分片重组模块不会在模块加载时直接全局启用。它们对外提供 nf_defrag_ipv4_enable() 和 nf_defrag_ipv6_enable() 函数,通过调用这些函数向 Netfilter hook 点注册分片重组钩子。
图 1.5 展示了 nf_defrag_ipv4 分片重组模块及对应的 Netfilter IPv4 hook 点: 该模块内部通过 ipv4_conntrack_defrag() 函数来进行网络报文的分片重组。该函数以 -400 的优先级注册为 Netfilter Prerouting 和 Netfilter Output hook 点的钩子函数。以确保报文在遍历 -200 优先级注册的 conntrack 钩子函数之前遍历它。
在注册 ct 系统自身的钩子函数之前,ct 系统会调用 nf_ct_netns_get() 函数,该函数会分别调用 nf_defrag_ipv4_enable() 函数或其对应的 IPv6 函数。因此,defrag 钩子函数与 conntrack 钩子函数一起被注册。defrag 钩子函数没有引用计数,一旦注册了该钩子函数,它就会一直保持注册状态(直到有人显式的删除/卸载该内核模块)。
1.7 hook 点概述
图 1.6 通过前面提到的 conntrack 和 defrag 钩子函数以及 Iptables 链来进行总结。
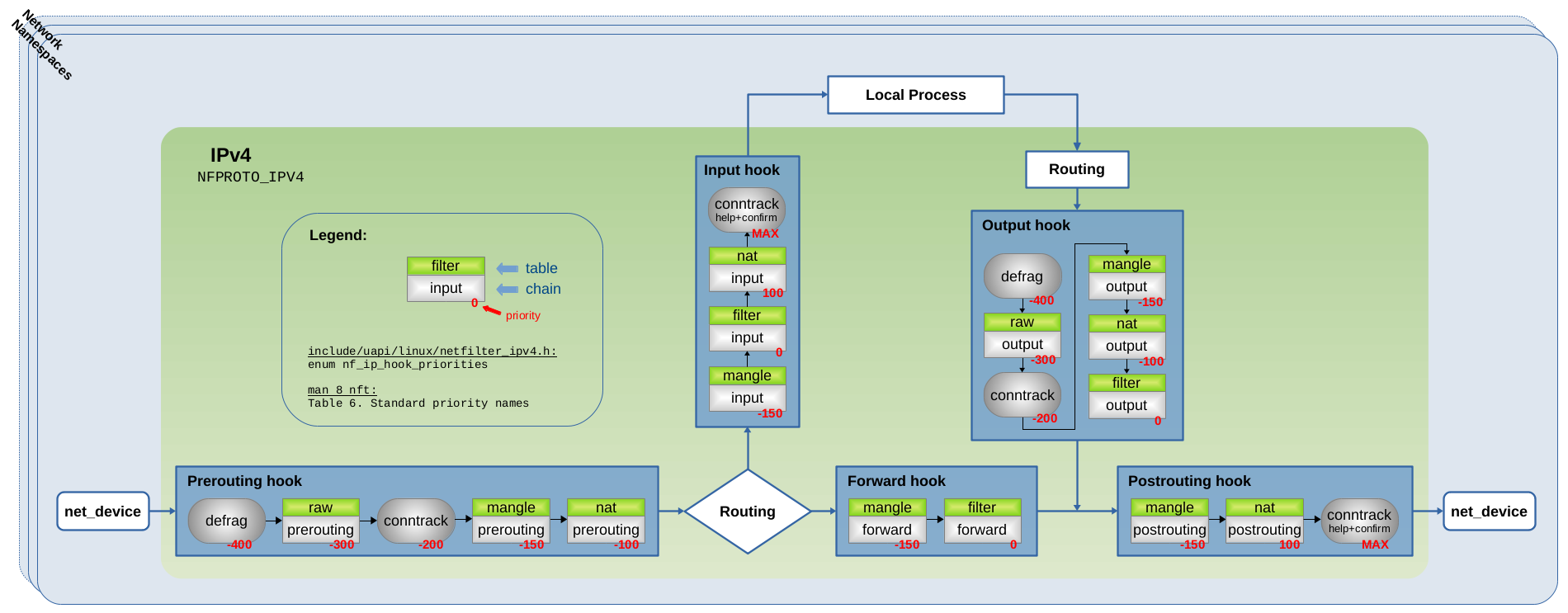
图 1.6:Conntrack + Defrag 钩子函数,以及注册到 IPv4 Netfilter hook 点的 Iptables 链
如图 1.6 所示,所有类型的报文(由本地套接字接收/本地套接字生成/转发):它们都会首先遍历 Prerouting 或 Output 这个两个 hook 点的分片重组钩子函数中的其中一个。这就保证了在 ct 系统看到分片报文之前对其进行分片重组。随后,报文遍历 raw 表的 Iptables 链(如果存在/正在使用),然后遍历 conntrack 主要的钩子函数(优先级为 -200 的钩子函数),之后遍历其他 Iptables 链,例如:常用于报文过滤的优先级为 0 的链。最后,报文遍历 conntrack “help + confirm” 钩子函数中的其中一个。
1.8 CT 系统是如何工作的
ct 系统在 central table 中维护其正在跟踪的连接,每个跟踪的连接都由一个 struct nf_conn 的实例表示。该结构包含 ct 系统在跟踪观测连接时学到的所有必要细节。从 ct 系统的角度来看,每个遍历其主要钩子函数(优先级为 -200 的钩子函数)的报文都会出现以下可能的四种情况:
-
- 该报文是其跟踪连接的一部分或与其相关。
-
- 该报文是尚未跟踪连接的第一个包。
-
- 该报文是一个无效报文(已损坏或其他原因)。
-
- 该报文被标记为 NOTRACK,ct 系统将会忽略该报文。
我们以从接口上收到一个报文,该数据包穿过 Netfilter Prerouting 和 Input hook 点,然后由本地套接字接收为例。
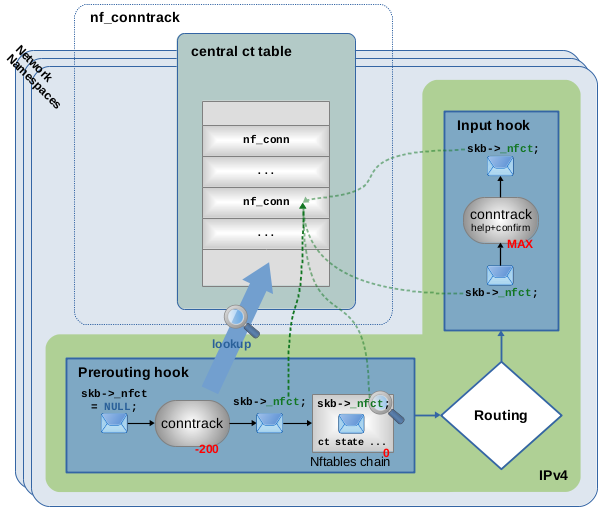
图 1.7:报文在 Prerouting hook 点中遍历 ct 主要钩子函数(优先级 -200),在 central ct 表中查找发现报文属于已跟踪的连接,报文被赋予指向该连接实例的指针。
第一种可能:
如图 1.7 所示,传入的报文是已跟踪连接的一部分。当该报文遍历 conntrack 主要钩子函数(优先级为 -200 的钩子函数)时,ct 系统首先对其执行初始有效性检查。如果报文通过了该检查,ct 系统就会查找 central 表以找到可能匹配的连接。在本示例的场景下,会找到匹配项,并向数据包提供指向匹配的连接跟踪实例的指针。每个报文的 skb 拥有一个 _nfct 成员变量,这意味着报文被 ct 系统进行“标记”或“分类”。此外,ct 系统将会分析报文的 4 层协议信息,并将最新的协议状态及详细信息保存到其连接跟踪实例中。
然后报文将继续通过其他钩子函数和网络协议栈。其他内核组件(例如,具有连接跟踪表达式(CONNTRACK EXPRESSION)规则的 Nftables)现在无需进一步查找 ct 表即可通过简单地解引用 skb->_nfct 指针就可获取有关报文的连接信息。
图 1.7 中,优先级为 0 的 Nftables 链挂载在 Prerouting hook 点,如果在该链中创建一条带有 ct state established 表达式的规则,该规则将会被匹配。报文在被本地套接字接收之前,最后一件事就是遍历 Input Hook 点中的 conntrack “help + confirm” 钩子函数。在本例中,该函数不会有任何操作,该钩子函数主要是针对其他特殊情况的。
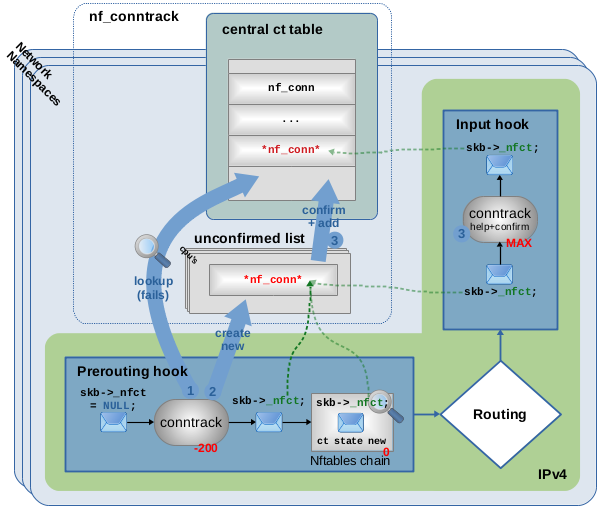
图 1.8:报文遍历 ct 主要钩子函数(优先级 -200),在 central ct 表中未找到匹配项,报文被视为新连接的第一个数据包,创建新连接并向报文提供指向它的指针,新连接将在稍后被 “confirmed” 并将 “help + confirm” 钩子函数(优先级 MAX)添加到 ct 表中。
第二种可能:
如图 1.8 所示,传入报文是 ct 系统尚未跟踪的新连接的第一个数据包。当该报文遍历 conntrack 主要钩子函数(优先级 -200)时,我们假设它已经通过了有效性检查,在 ct 表 (1) 中查找没有找到匹配的连接。因此,ct 系统认为该报文是新连接的第一个数据包。创建新的 struct nf_conn 实例 (2),并将报文的 skb->_nfct 成员初始化为指向该实例的指针。
ct 系统此时将新连接视为 “unconfirmed”。因此,新的连接实例尚未添加到 central 表中,暂时存放在未确认列表(unconfirmed list)上。此外,ct 系统将会分析报文的 4 层协议信息,并将协议状态和详细信息保存到其连接跟踪实例中。然后报文将继续通过其他钩子函数和网络协议栈。
图 1.8 中,优先级为 0 的 Nftables 链挂载在 Prerouting hook 点,如果在该链中创建一条带有 ct state new 表达式的规则,该规则将会被匹配。报文在被本地套接字接收之前,最后一件事就是遍历 Input Hook 点中的 conntrack “help + confirm” 钩子函数。该函数的工作是 “confirm” 新连接,该函数设置相应地状态位并将连接跟踪实例从未确认列表移动到实际的 ct 表 (3) 中。这么设计的原因是,报文可能会在 conntrack 主钩子函数和 conntrack “help + confirm” 钩子函数之间的某个地方被丢弃,例如,被 Nftables 规则、路由系统丢弃。同时也是为了防止 “unconfirmed” 新连接弄乱central ct 表及消耗大量不必要的 CPU 资源。
例如,存在 iif eth0 ct state new drop 这样的 Nftables 规则,用来防止新连接进入 eth0 接口。因此,与之匹配的连接应该被丢弃,该连接跟踪根本不会出现在 ct 表中。在此情况下,第一个连接报文将在 Nftables 链中被丢弃,并且永远不会到达 conntrack “help + confirm” 钩子函数。因此,新的连接实例将永远不会被确认并在未确认列表(unconfirmed list)中死亡。换句话说,新的连接实例将会与丢弃的报文一起被删除。这在有人进行端口扫描或发起 TCP SYN 泛洪攻击时,很有意义。
正常情况下 client 正在尝试通过发送 TCP SYN 报文建立 TCP 连接,如果没有收到对端的任何回复,它仍然会发送几个 TCP SYN 重传报文。如果您设置了 ct state new drop 规则,则此机制可确保 ct 系统(denied!)新的连接。
第三种可能:
如果 ct 系统认为报文无效。例如,当报文未通过图 7 或 8 中 Prerouting hook 点的 conntrack 主钩子函数的初始有效性检查。例如,由于无法解析损坏或不完整的协议头。当无法对报文的 4 层协议进行详细分析时,也会发生这种情况。例如,对于 TCP 报文,ct 系统会观察接收窗口和序列号,如果序列号不匹配则报文将被视为无效(丢弃无效报文并不是 ct 系统的工作,ct 系统将这个决定留给内核协议栈的其他模块)。如果 ct 系统认为报文无效,只是简单地将 skb->_nfct=NULL。如果您将 ct state invalid 的 Nftables 规则放置在图 1.7 或 1.8 中的示例链中,则该规则将会被匹配。
第四种可能:
其他内核组件(如 Nftables)通过 “do not track” bit 位标记报文,告诉 ct 系统忽略它们。为了与 Nftables 一起使用,您需要创建一个优先级小于 -200(例如 -300)的链,这确保它能在 ct 主钩子函数被遍历之前遍历,并在该链中添加一条带有 notrack 语句的规则。如果您将带有 ct state untracked 表达式的 Nftables 规则放置在图 1.7 或 1.8 中的示例链中,则该规则将会被匹配。
1.9 连接跟踪实例的生命周期
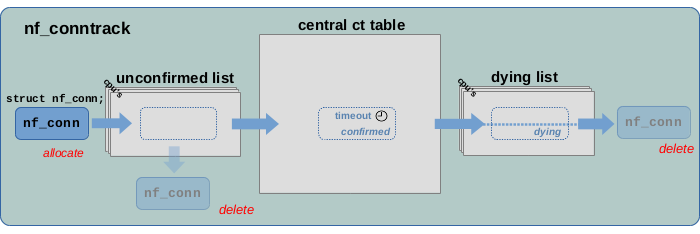
图 1.9:连接跟踪实例的生命周期
图 1.9 展示了连接跟踪实例从创建到删除的生命周期。一个新的连接首先被添加到未确认列表(unconfirmed list)中。如果触发其创建的网络报文在到达 ct 系统的 help + confirm 钩子函数之前被丢弃,则该连接将从未确认列表(unconfirmed list)中被删除。如果报文通过了 help + confirm 钩子函数,则该连接将被移至 central ct 表中并被标记为 “confirmed”。这条连接将会一直存在,直到该连接超时被视为 “expired”。如果在一段时间内没有收到该连接跟踪新的网络报文,则该连接将被视为 “expired”。一旦“expired”,连接就会被移至死亡列表(dying list),并被标记为“dying”,在此之后将被删除。
可以通过 conntrack 命令列出所有连接跟踪实例,每行输出的第三列为该连接的到期时间。(以下示例中为 431998 秒):
conntrack -L
tcp 6 431998 ESTABLISHED src=192.168.2.100 ...
...
整个系统只存在一个 central ct 表,但每个网络命名空间和每个 CPU 都有单独的未确认列表(unconfirmed list)和死亡列表(dying list)。
2. CT 系统(CT System’s)底层实现
2.1 CT 表
ct 系统在 central 表中维护正在跟踪的连接,由于几乎每个报文都需要对该表执行查找操作,为了提高查找效率,该表被设计为 Hash 表。
为什么采用 Hash 表? Hash 表被定义为一个关联数组,一种维护 key-value 键值对的数据结构。当 key 本身太复杂而无法直接用作数组索引的情况下(理论上所有可能 key 的总数过于庞大),采用 Hash 表将会非常有用。当基于 key 查找 value 时,方法是通过 key 计算出简单的 hash 值(这样就保证其值的范围大小一定),以便可以用作数组的索引(例如,hash 值的大小 8 bit,这样数组的大小为 2^8=256 个条目(entry))。
采用 Hash 表的优点是:hash 计算以及数组索引查找都可以在恒定时间内完成,这意味着 hash 表查找算法的时间复杂度为 O(1)。缺点是:由于 hash 值范围有限,hash 冲突不可避免(不同 key 具有相同 hash 值)。因此,hash 表数组中的每个 entry 不仅仅包含单个 value,而是一条包含产生 hash 冲突的所有 value 的双向链表。这意味着,hash 表查找算法的时间复杂度最多为 O(1),最坏为 O(n):在 hash 计算找到数组 index 之后,需要遍历该 hash 桶的双向链表以找到正确的 value。为了实现这一点,通常将 key 作为 value 本身的一部分进行保存,以便于进行通过 key 的比较找到对应的 value。
可以对该表执行三个相关操作:对该表执行查找以找到与报文相对应的现有连接跟踪示例;将新的连接跟踪实例添加到表中;当连接“过期(expires)”时,从表中删除该连接。 ct 系统为每个连接的 “老化(age)”和“过期(expire)” 维护一个独立的定时器。
ct 表是一个中心表,整个系统只存在这一张表,而不是每个网络命名空间一张表。为了避免不同网络命名空间中相似流量(key(ip、port)相同)的 hash 冲突,每个命名空间在 hash 计算时都有一个特定于命名空间的 hash 种子 hash_mix。为了连接跟踪能够区分,每个被跟踪的连接实例都拥有一个对其所属网络命名空间的引用,在连接跟踪查找的过程中还会检查该引用。
2.2 Hash 表的 key:元组(tuples)
对于 ct 系统而言,hash 表需要能够轻松地从报文的 3 层和 4 层协议头信息中提取出 key,并且能够明确的指出该报文属于哪个连接。 ct 系统将 key 称为 “元组”,并将其保存在 struct nf_conntrack_tuple 数据类型中。nf_ct_get_tuple() 函数用于从报文的协议头信息中提取所需要的数据,并将其值填充该数据类型的成员变量。图 2.1 为基于 TCP 报文的示例:
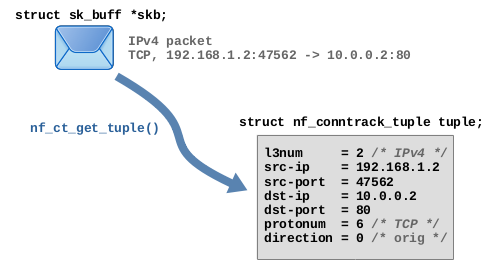
图 2.1:从 TCP 报文中提取元组
对于 TCP 而言,元组包含源 IP 和目的 IP 以及 TCP 源端口和目的端口,它们代表一条连接的两个端点。struct nf_conntrack_tuple 结构体非常灵活,可以保存提取到的多个不同的 3 层和 4 层协议头数据。该结构体成员通过 union 类型实现,能够根据协议的不同包含不同的内容。从语义上讲,该结构体包含以下内容:
- OSI Layer 3
- Protocol number: 2 (IPv4) or 10 (IPv6)
- Source IP address
- Destination IP address
- OSI Layer 4
- Protocol number: 1 (ICMP)/ 6 (TCP)/ 17 (UDP)/ 58 (ICMPv6)/ 47 (GRE)/ 132 (SCTP)/ 33 (DCCP)
- Protocol-specific data
- TCP/UDP: source port and destination port
- ICMP: type, code and identifier
- …
- Direction: 0 (orig) / 1 (reply)
2.3 Hash 表的 value:struct nf_conn 结构体
Hash 表中的 value 为 struct nf_conn 结构体保存的连接跟踪。该结构体有很多的成员变量,并且可以在运行时根据 4 层协议的内容动态扩展。
图 2.2 是该结构体的简化展示,只包含了主要的成员变量。它包含一个引用计数器、超时时间、该连接所属的网络命名空间的引用、连接状态 bit 位以及 4 层协议的相关信息(对于 TCP 而言则是 TCP 序列号等内容)。
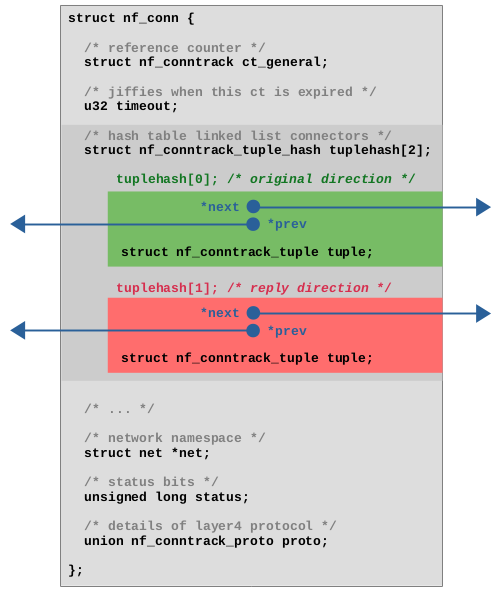
图 2.2:struct nf_conn 结构体。
在 Hash 表进行查找时,如果存在 Hash 冲突就必须通过比较 key 来找出真正的 value,因此必须将 key(struct nf_conntrack_tuple 元组)作为 value(struct nf_conn)的一部分进行保存。
对于 ct 系统,它必须能够在 Hash 表中查找报文在原始数据流方向(original direction)的跟踪连接,还必须能够查找报文在回复方向(reply direction)的跟踪连接。两者元组(tuples)不同生成的 Hash 值也不同,但必须能够找到相同的 struct nf_conn 结构体。因此,tuplehash[2] 被定义为包含两个元素的数组,每个元素均包含一个元组(tuple)和一个将该元素连接到 Hash 表链表的指针。第一个元素(如图 2.2 中的绿色所示)代表原始方向,该 tuple 的 direction 变量设置为 0 (orig)。
第二个元素(如图 2.2 中的红色所示)表示回复方向,该 tuple 的 direction 变量设置为 1(reply)。每个被跟踪的连接只存在一个 struct nf_conn 实例,该实例将会被添加到 Hash 表中两次,一次用于原始方向,一次用于回复方向。
2.4 查找现有连接
如图 2.3 所示,TCP 报文正在遍历 Netfilter Prerouting hook 点的 ct 钩子函数。该钩子函数的主要内容是调用 nf_conntrack_in() 函数,在 nf_conntrack_in() 函数内部调用 resolve_normal_ct() 函数进行 ct 查找。在此示例中,我们假设 TCP 报文所属的连接此时已被 ct 系统跟踪(换句话说,这不是 ct 系统看到该连接的第一个报文)。
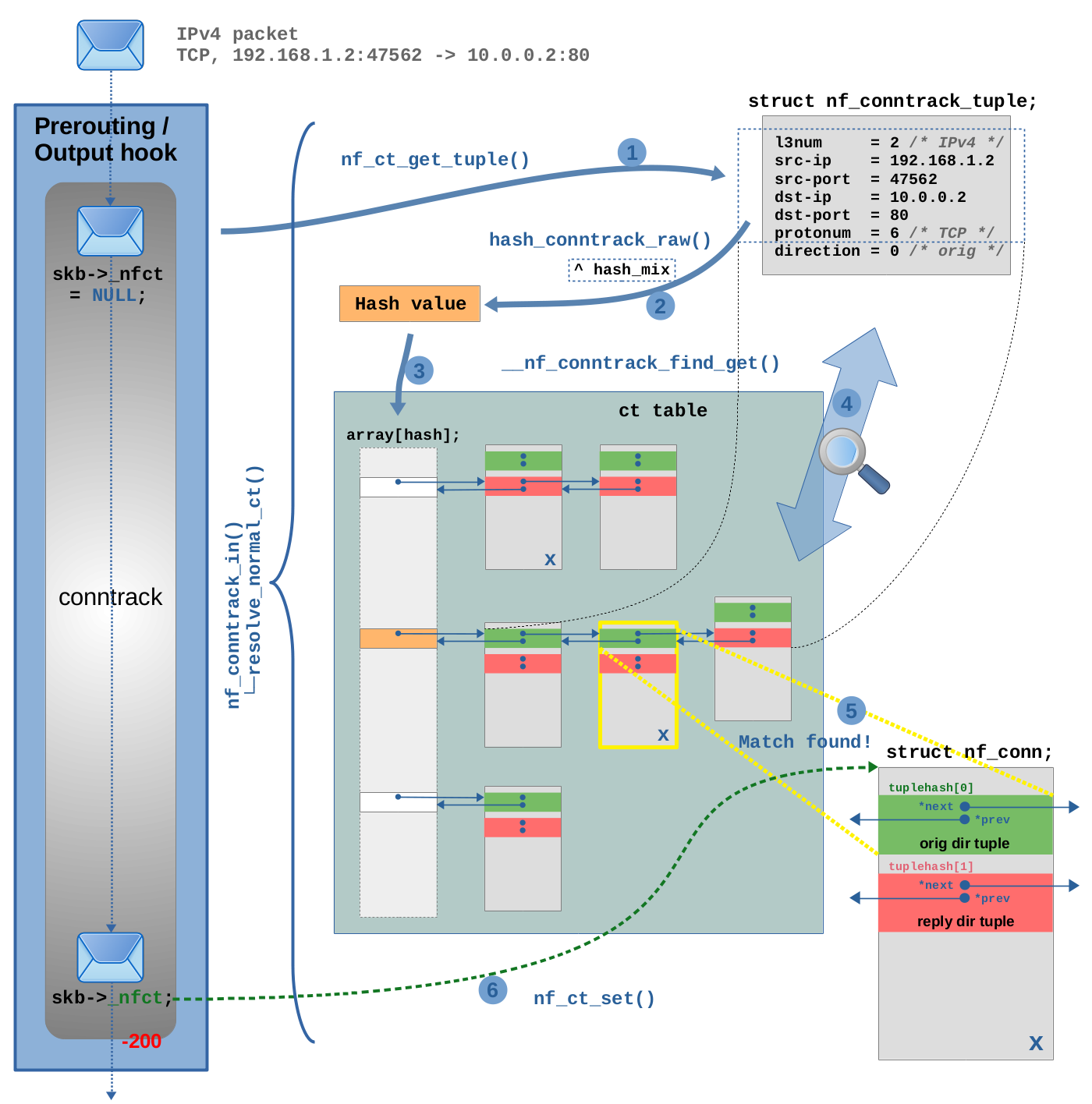
图 2.3:连接跟踪查找的详细流程。
第 (1) 步,调用 nf_ct_get_tuple() 函数从 TCP 报文获取元组,即 Hash 表的 key(与图 2.1 所示的内容相同)。此时,元组的 direction 变量默认设置为 0 (orig),但此时 ct 系统尚不知道 TCP 报文是所跟踪连接的原始方向还是回复方向。
第 (2) 步,调用 hash_conntrack_raw() 函数,根据元组成员变量计算 Hash 值。如图 2.3 中的矩形虚线所示,direction 变量不参与 Hash 计算,但网络命名空间的 Hash 种子 hash_mix 会参与 Hash 计算。
通过调用步骤 (3)、(4) 和 (5) 中的 __nf_conntrack_find_get() 函数执行 Hash 表查找: 如图 2.3 中的橙色所示,在 (3) 步,Hash 值用作 Hash 表数组索引以定位正确的 Hash 桶。在此示例中,该 Hash 桶已包含三个 struct nf_conn 实例(三个连接跟踪在此 Hash 值产生冲突)。
在 (4) 步,遍历该 Hash 桶链表,并将每个连接实例结构体成员 tuplehash[] 内的元组与步骤 (1) 中从 TCP 报文生成的元组进行比较,如果元组的所有成员变量(direction 除外)与网络命名空间都匹配,则该连接被视为匹配。
在 (5) 步中找到匹配项,在图 2.3 中匹配项存在于 Hash 表的两个不同位置(用 X 标记了匹配实例)。其中一个,通过 tuplehash[0] 指针连接到 Hash 桶链表(原始方向,以绿色显示),另外一个,通过 tuplehash[1] 指针连接到 Hash 链表(回复方向,以红色显示)。在步骤(5)中匹配的是 tuplehash[0](绿色),这意味着该 TCP 报文属于该跟踪连接的原始方向。
在 (6) 步,通过调用 nf_ct_set() 函数,将报文的 skb->_nfct 指向匹配的 struct nf_conn 实例。最后,在报文完成遍历 ct 钩子函数之前,对报文的 4 层协议进行校验(示例中为:TCP)。
2.5 添加新连接
如果未查找到匹配,在这种情况下,TCP 报文将被视为新连接的第一个报文,该连接尚未被 ct 系统跟踪。resolve_normal_ct() 函数将通过调用 init_conntrack() 创建新的跟踪连接实例。工作原理如图 2.4 所示:
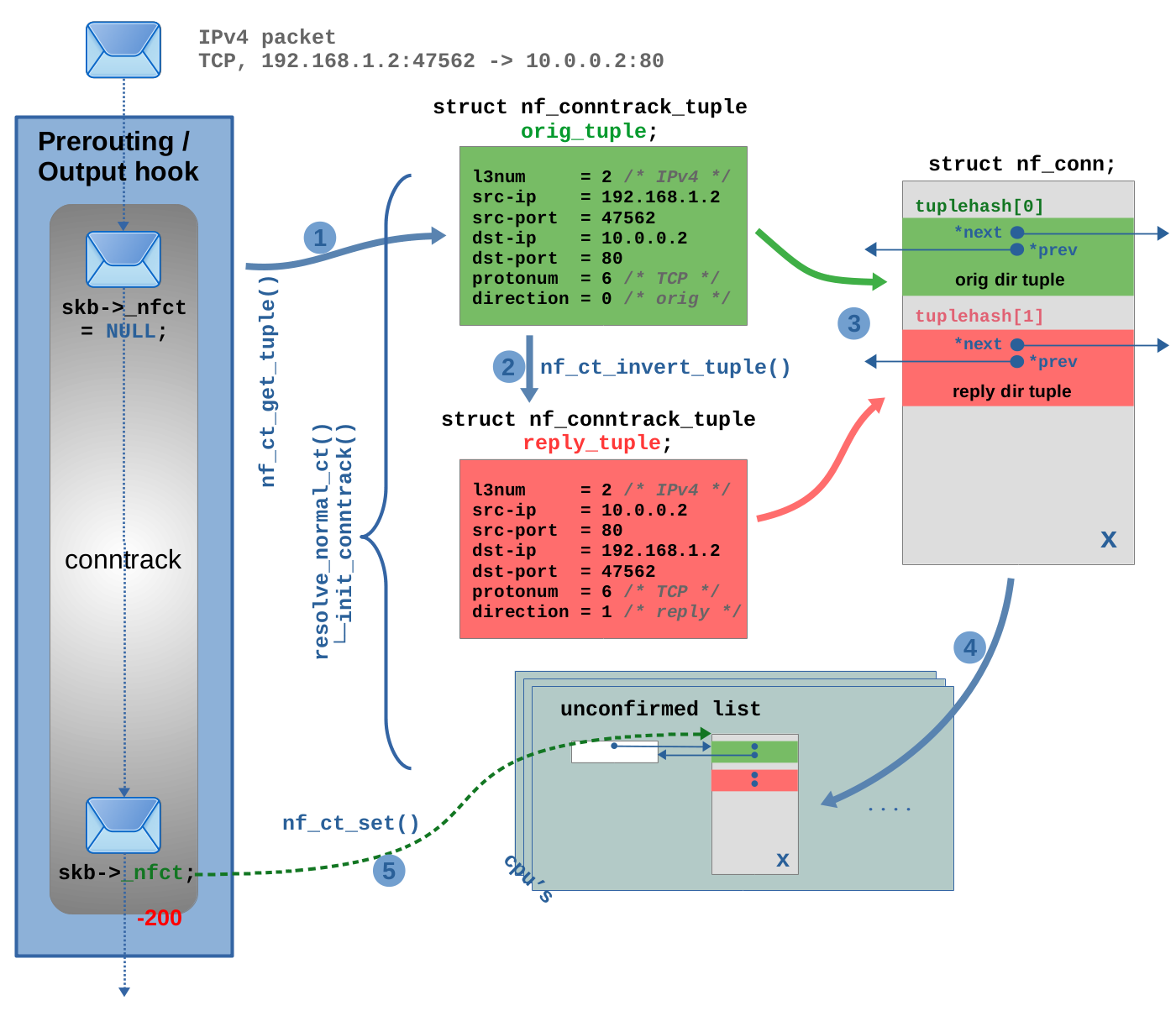
图 2.4:创建新的跟踪连接实例。
首先,由于有两个方向的数据流,因此创建两个方向的元组。第一个名为 orig_tuple,在图 2.4 中以绿色显示(也就是图 2.3 的步骤 (1) 中所示的在连接查找期间由 nf_ct_get_tuple() 函数创建的元组,这里重新拿来使用)。图 2.4 的步骤 (1) 只是为了方便展示所有相关数据。orig_tuple 表示原始数据流方向,其 direction 成员变量方向设置为 0(orig)。这是 ct 系统看到该连接的第一个报文的数据流向,在本例中为:192.168.1.2:47562 -> 10.0.0.2:80。
在步骤 (2) 中调用 nf_ct_invert_tuple() 函数,它创建第二个元组:reply_tuple,如图 2.4 中的红色所示。该元组代表回复数据流方向,在本例中为:10.0.0.2:80 -> 192.168.1.2:47562,其 direction 成员变量方向设置为 1(reply)。nf_ct_invert_tuple() 函数不根据 TCP 报文创建 reply_tuple 元组,该函数基于现有元组创建相反数据流方向的元组。它通过使用 orig_tuple 作为输入参数,创建 reply_tuple 元组。在本例中,nf_ct_invert_tuple() 函数只是翻转源和目标 IP 地址以及源和目标 TCP 端口。该函数会根据协议的不同,所做的事情也不同:例如,在 ICMP 的情况下,如果 orig_tuple 描述 ICMP echo-request(type=8, code=0, id=42),则反转的 reply_tuple 将描述 echo-reply(type=0, code=0, id=42)。
在步骤(3)中,分配新的 struct nf_conn 实例并初始化其成员变量,这两个元组将会被插入到该实例的 tuplehash 数组中。此时,这个新跟踪连接实例仍被视为 “unconfirmed”(未确认),在步骤 (4) 中,它被添加到 unconfirmed list(未确认列表中),每个网络命名空间和每个 CPU 都存在该链表。步骤 (5) 与图 2.3 查找过程中的步骤 (6) 完全相同,初始化报文的 skb->_nfct 指向新的连接实例。最后,在报文完成遍历 ct 钩子函数之前,对报文的 4 层协议进行校验(示例中为:TCP)。
在此示例中,我假设报文在经过内核协议栈以及一个或多个 Nftables chains 和 rules 时不被丢弃。最后,报文遍历其中一个 conntrack “help+confirm” 函数(优先级为 MAX)。在该函数中,新连接将得到“confirmed”(确认)并添加到 ct Hash 表中。详细过程如图 2.5 所示:
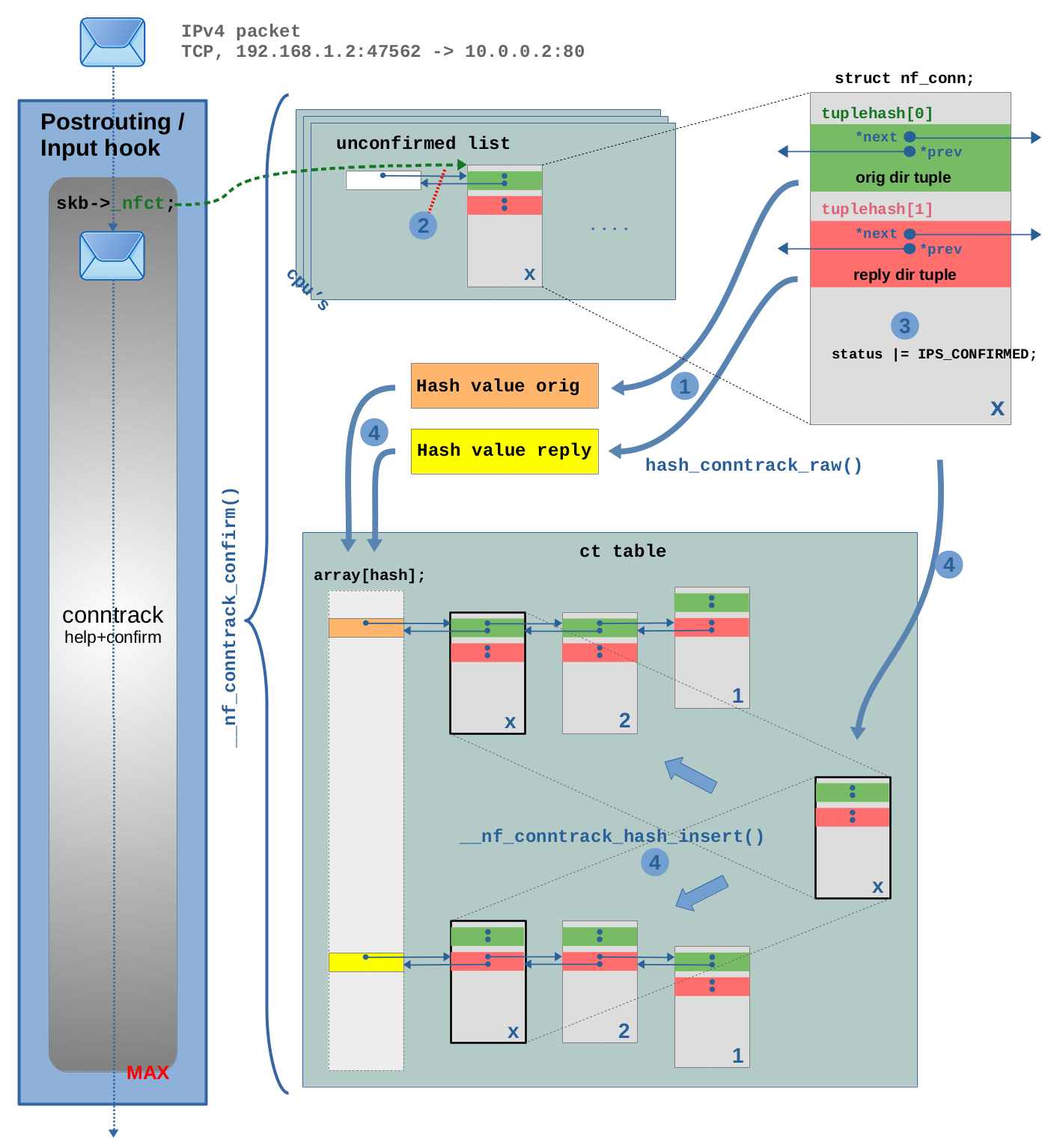
图 2.5:确认新的连接跟踪实例并将其添加到 ct Hash 表中
仅当属于该报文(示例中 TCP 报文)的跟踪连接尚未“unconfirmed”时,函数 __nf_conntrack_confirm() 才会执行。这是通过检查 struct nf_conn 结构体的 status 成员变量的 IPS_CONFIRMED_BIT bit 位确定的,此时该 bit 为 0。
在步骤 (1) 中,分别根据 orig_tuple 和 struct nf_conn 实例的 reply_tuple 计算两个 Hash 值。
然后在步骤(2)中,将 struct nf_conn 实例从 unconfirmed list 中删除。
在步骤(3)中,status 成员变量的 IPS_CONFIRMED_BIT bit 位被设置为 1,代表 “confirming” 在进行确认。
最后,在步骤 (4) 中,实例被添加到 ct 表中。Hash 值用作数组索引,以定位正确的 Hash 桶。最后 struct nf_conn 实例分别使用 tuplehash[0](原始方向)和 tuplehash[1](回复方向)添加到两个 Hash 桶的链表中。
2.6 移除连接
从 ct 表中移除连接实例意味着,该连接实例通过 clean_from_lists() 函数将从表中两个 Hash 存储桶的链表中移除。但是,该特定连接实例尚未被真正删除。
连接生命周期、引用计数
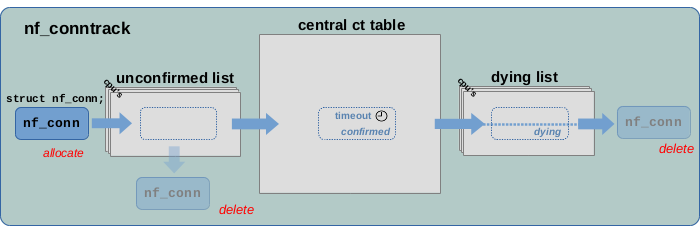
图 2.6:被跟踪连接实例的生命周期
如图 2.6,在内部,生命周期是通过引用计数来处理的。每个 struct nf_conn 实例都有一个名为 struct nf_conntrack ct_general 的引用计数器(如图 2.2)。该结构体包含一个名为 use 的 atomic_t 整数。当将 struct nf_conn 实例添加到 ct 表时,use 加 1,当从表中删除该实例时,use 减 1。当每个网络报文通过其 skb->_nfct 成员变量引用 struct nf_conn 实例,use 会加 1,并在 skb 被释放减 1。 ct 系统 API 提供了递增/递减 use 的函数,通过 nf_conntrack_get() 函数递增 use,通过 nf_conntrack_put() 函数递减 use。struct nf_conn 声明包含一条注释,对引用计数行为的行为进行了说明。
2.7 连接删除
当 nf_conntrack_put() 函数将 use 引用计数器减为 0 时,它会调用 nf_conntrack_destroy() 函数删除 struct nf_conn 实例。该函数通过调用一堆函数来完成这一点。它调用 nf_ct_del_from_dying_or_unconfirmed_list() 函数,然后调用 nf_conntrack_free() 函数,该函数执行真正的删除。换句话说,当引用计数器递减至 0 时,struct nf_conn 实例当前要么位于 unconfirmed list (未确认列表)要么位于 dying list(死亡列表)。
如图 2.6,实际上只有两种情况下会产生连接删除: 一种情况是:当连接实例位于 unconfirmed list(未确认列表)中时,如果触发其创建的网络报文在到达 conntrack “help+confirm” 钩子函数之前被丢弃,则会发生连接被删除。报文丢弃意味着 skb 正在被删除/释放,skb 释放调用 skb_release_head_state() 函数,该函数调用 nf_conntrack_put() 将引用计数器 use 递减为 0,从而触发 nf_conntrack_destroy()。
另一种情况是:当连接实例位于 dying list(死亡列表)中时。
2.8 连接超时
一旦将跟踪的连接实例添加到 ct 表并标记为“confirmed”(已确认)时,如果该连接没有继续收到网络报文时,就会被设置一个超时定期用于 “expire”(过期)。通常,当网络报文被识别为属于跟踪的连接时(=在 ct 表中找到了匹配项),都会重置该连接的超时定时器。因此,只要跟踪的连接保持繁忙,它就不会过期。如果一段时间内没有检测到流量,它将会过期。
超时时间多长,很大程度上取决于 4 层协议的类型和状态。常见的超时时间为 30s - 5day。例如,当 4 层协议为 TCP 时,CT 系统在连接当前处于 TCP 3 次握手过程中时,设置为较短的超时时间(默认为 120 秒)(即:跟踪连接是由于 TCP SYN 报文创建,并且当前 ct 系统正在等待回复方向上的 TCP SYN ACK)。一旦 TCP 连接完全建立,它将设置为较长的超时时间(默认为 5 天),因为 TCP 连接的寿命比较长。超时时间的默认值是硬编码(代码请参阅 nf_conntrack_proto_tcp.c 中 tcp_timeouts[] 数组中列出的 TCP 协议超时时间),系统管理员,可以通过 sysctl 读取并修改当前网络命名空间的 /proc/sys/net/netfilter/nf_conntrack_*_timeout* 文件来修改超时时间的默认值,该文件中超时时间的单位是秒。
超时处理基于内核的 jiffies 软件时钟机制,struct nf_conn 实例都拥有一个整形成员变量 timeout(如图 2.2)。例如,当连接的超时时间设置为 30 秒时,timeout 变量会简单地设置为:“now” 对应的 jiffies + 30 * HZ 的偏移量。启用超时以后,nf_ct_is_expired() 函数通过将 timeout 值与系统当前的 jiffies 值进行比较,已检查是否超时。
jiffies: 与其他内核组件一样,ct 系统利用 Linux 内核的 “jiffies” 软件时钟机制,它是一个全局整数,在系统启动时初始化为 0,并通过定时器中断间隔加 1。该间隔时间由 HZ 确定,例如在(Debian,x86_64)系统重 HZ 被设置为 250,这意味着 jiffies 每秒递增 250 次,因此间隔时间为 4 ms。
不要将连接超时与 ct 系统的超时扩展(timeout extension)混淆,该扩展是在连接超时处理之上实现的一些附加可选机制,它增加了更多超时处理的灵活性,例如:允许通过 Nftables 设置连接超时。
2.9 GC 工作队列
ct 系统如何检查每个跟踪的连接是否过期?
ct 系统使用内核的工作队列机制在内核工作线程内定期运行垃圾回收函数 gc_worker。它遍历 central ct 表中跟踪的连接实例,并使用 nf_ct_is_expired() 函数检查它们是否过期。如果发现连接过期,则调用 nf_ct_gc_expired() 函数。通过一堆函数,该连接的 status 成员变量的 IPS_DYING_BIT bit 位被设置,该连接从 central ct 表中 removed(移除)并添加到 dying list(死亡列表)中。调用 nf_conntrack_destroy() 函数以确保没人使用引用计数,然后再次从死亡列表中移除该连接,并最终将其删除。
2.10 死亡列表
为什么会有死亡列表? 默认情况下,垃圾回收将过期的跟踪连接从 ct 表中移除,设置 IPS_DYING_BIT 并将其添加到死亡列表中,然后再次将其从死亡列表中移除,并最终删除它。默认情况下所有这些都是由 nf_ct_gc_expired() 函数完成。
可能有人认为,默认情况下,死亡列表根本不需要。然而在特殊情况:当您使用 conntrack 用户态工具和 -E 选项实时查看 ct 事件时,会将 ct 系统内的某些事件(例如,创建新的连接跟踪、删除连接等)传递给用户空间。这些操作可能会发生阻塞,这就是为什么在这种情况下垃圾回收的后半部分(从死亡列表中移除连接并删除它)需要推迟到另一个工作线程。不能允许该事件机制阻塞或减慢垃圾回收工作线程本身。
3. CT 实战
3.1 概览
Iptables/Nftables 用于匹配跟踪连接状态的常用语法如下所示:
#Nftables example
ct state established,related
#Iptables example
-m conntrack --ctstate ESTABLISHED,RELATED
在本文中,我们将探讨:保存 CT 系统内状态信息的变量的实现的行为方式以及从 Iptables/Nftables 和命令行工具 conntrack 的角度观测 CT 系统。此处涉及的变量如图 3.2 所述,有两个变量保存状态信息。
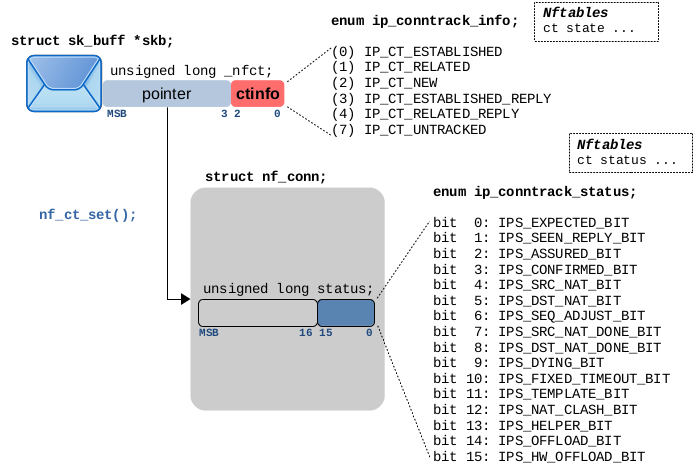
图 3.2:遍历 ct main 钩子函数(优先级-200)后的网络报文,属于被跟踪的连接,status 指定内部连接状态,ctinfo 指定连接状态,报文相对于连接的方向以及报文与连接的关系。
3.2 状态变量
如图 3.2 所示,status 是 struct nf_conn 的整数成员变量,其低 16 bit 用作所跟踪连接的状态和管理 bit,其每个 bit 的名字和含义通过 enum ip_conntrack_status 提供。图 3.3 表格进行详解说明。
其中一些 bit 表示 ct 系统确定的跟踪连接的当前状态(通过分析观测到的网络报文),而其他 bit 则表示内部管理设置。剩余的 bit 为指定在特定情况下跟踪连接所执行的操作,例如 NAT、硬件卸载、用户自定义的超时时间等。
Iptables/Nftables:其中一些 bit 位可以通过在 Iptables/Nftables 规则中使用 conntrack 表达式直接进行匹配。图 3.3 中的表显示了对可匹配 bit 位执行此操作的确切语法。如果您的链位于 Netfilter Prerouting 或 Output 钩子中,并且您的规则使用这种类型的表达式,那么您的链的优先级必须 > -200,以确保网络报文在遍历完 ct 主钩子函数之后遍历它(见图 3.1)。
Conntrack:当使用用户空间工具 conntrack -L 选项列出当前跟踪的连接或执行 cat /proc/net/nf_conntrack,一些状态 bit 位将在输出结果中显示。图 3.3 展示了其使用语法。
bit 0: IPS_EXPECTED
预期连接(Expected connection):当新连接的第一个报文遍历 ct main 钩子函数时,将创建一个新的连接跟踪。如果这个新的连接跟踪被识别为预期连接,则该 bit 位被置位。例如,当使用 FTP 协议的 ct helper 时,就会发生这种情况(详细参见 FTP extension)。预期的连接通常是 “FTP data” TCP 连接 ,它与已建立的 “FTP command” TCP 连接相关。如果该 bit 为被设置,则 ctinfo 将设置为 IP_CT_RELATED。
| conntrack 表达式匹配该 bit | |
|---|---|
| Nftables | ct status expected |
| Iptables | -m conntrack –ctstatus EXPECTED |
bit 1: IPS_SEEN_REPLY
报文已经被双向看到(该 bit 位可以 set,不能 unset):一旦 ct 系统看到回复方向上的第一个报文,就会设置该 bit。
| conntrack 表达式匹配该 bit | |
|---|---|
| Nftables | ct status seen_reply |
| Iptables | -m conntrack –ctstatus SEEN_REPLY |
| 通过 conntrack 命令或者 proc 文件查看 | |
|---|---|
| conntrack -L | [UNREPLIED] |
| cat /proc/net/nf_conntrack | [UNREPLIED] |
bit 2: IPS_ASSURED
此跟踪的连接永远不应该提前过期:如果 ct 系统看到的报文 4 层连接完全建立并且可以看到双向流量,则设置此 bit 位。对于 TCP,一旦看到完整的 TCP 3 次握手,该 bit 就会被设置。在 UDP 的情况下,当已看到双向流量并且现在又看到一个报文时,该 bit 就会被设置。在 ICMP(例如 ping:echo-request + echo-reply)的情况下,不会设置该 bit 位。未设置该 bit 位的跟踪连接可能会成为 “early drop”(早期丢弃)机制的受害者。当 ct 系统跟踪的连接数量增长非常高并达到某个最大阈值(这取决于 central ct 表的配置大小)时,ct 系统开始删除未设置 assured 的连接以释放一些空间。
| conntrack 表达式匹配该 bit | |
|---|---|
| Nftables | ct status assured |
| Iptables | -m conntrack –ctstatus ASSURED |
| 通过 conntrack 命令或者 proc 文件查看 | |
|---|---|
| conntrack -L | [ASSURED] |
| cat /proc/net/nf_conntrack | [ASSURED] |
bit 3: IPS_CONFIRMED
这个被跟踪的连接已经被确认,原始报文已经离开设备:一旦代表新跟踪连接的报文(该连接看到的第一个报文)遍历了 ct 系统的主钩子函数(优先级 -200)和 ct help + confirm 钩子函数(优先级 MAX),该新的跟踪的连接将会被 “confirmed”(确认)并被添加到 central ct 表中,同时设置该 bit 位。
| conntrack 表达式匹配该 bit | |
|---|---|
| Nftables | ct status confirmed |
| Iptables | -m conntrack –ctstatus CONFIRMED |
bit 4: IPS_SRC_NAT
此跟踪的连接需要进行原始方向的 SRC NAT
| conntrack 表达式匹配该 bit | |
|---|---|
| Nftables | ct status snat |
| Iptables | -m conntrack –ctstate SNAT |
bit 5: IPS_DST_NAT
此跟踪的连接需要进行原始方向的 DST NAT
| conntrack 表达式匹配该 bit | |
|---|---|
| Nftables | ct status dnat |
| Iptables | -m conntrack –ctstate DNAT |
bit 6: IPS_SEQ_ADJUST
该跟踪连接需要调整 TCP 的顺序
bit 7: IPS_SRC_NAT_DONE
NAT 初始化 bit 位
bit 8: IPS_DST_NAT_DONE
NAT 初始化 bit 位
bit 9: IPS_DYING
此跟踪连接即将终止,已从列表中移除(不能 unset bit位):一旦所跟踪的连接超时,该 bit 位就会被设置,并且该连接将从 central ct 表中移除并添加到死亡列表中,随后它就会被删除。
| conntrack 表达式匹配该 bit | |
|---|---|
| Nftables | ct status dying |
bit 10: IPS_FIXED_TIMEOUT
此跟踪的连接具有固定的超时时间。
bit 11: IPS_TEMPLATE
此跟踪连接是一个模板。
bit 12: IPS_NAT_CLASH
此跟踪连接在插入时与现有实例发生冲突。
bit 13: IPS_HELPER
此跟踪连接通过 CT target 附加了一个 helper。
bit 14: IPS_OFFLOAD
该跟踪的连接已被卸载到流表中。
| 通过 conntrack 命令或者 proc 文件查看 | |
|---|---|
| conntrack -L | [OFFLOAD] |
| cat /proc/net/nf_conntrack | [OFFLOAD] |
bit 15: IPS_HW_OFFLOAD
该跟踪的连接已通过流表卸载到硬件。
| 通过 conntrack 命令或者 proc 文件查看 | |
|---|---|
| conntrack -L | [HW_OFFLOAD] |
| cat /proc/net/nf_conntrack | [HW_OFFLOAD] |
图 3.3:struct nf_conn status 成员变量的的最低有效 16 bit 位的名称和含义。
3.3 指针和 ctinfo
当网络报文遍历其中一个 ct 主钩子函数时(图 3.1 中优先级为 -200 的那些函数)并且清楚该报文属于哪个被跟踪的连接时,该报文的 skb->_nfct 将指向 central ct 表中相应 struct nf_conn 实例。该指针的最低 3 bit 并不是指针的一部分,它们被用作一个整数,在代码的中被称为 ctinfo。
内核内存管理确保用于保存 struct nf_conn 实例的内存地址是 8 字节对齐的,因此从指针中 mask 最低 3 bit 不会存在问题。当使用 _nfct 作为指针时,其最低 3 bit 被 mask,并设置为 0。nf_ct_get() 函数用于从 skb->_nfct 解引用指针和获取 ctinfo。nf_ct_set() 函数用于指针赋值和 ctinfo 写入 skb->_nfct。 3 bit 整数 ctinfo 的包含的含义是网络报文所属跟踪连接的当前状态、数据包的流向以及该报文与该连接关系。 ctinfo 值的名称和含义为 enum ip_conntrack_info 类型,图 3.4 对其详细进行解释。该表中描述的所有情况都可以通过在 Iptables/Nftables 规则中使用 conntrack 表达式进行匹配,如果您的链位于 Netfilter Prerouting 或 Output 钩子中,并且您的规则使用了这种类型的表达式,那么您的链的优先级必须 > -200,以确保网络报文在遍历完 ct 主钩子函数之后遍历它(见图 3.1)。
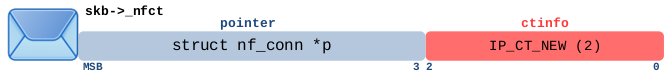
报文可以是以下情况中的任意一种:
- 所跟踪连接看到的第一个报文(例如 TCP SYN 报文,如果 ct 系统能够从头开始观察该连接的所有数据包);因此,刚刚为该数据包创建了一个新的 “unconfirmed ” 跟踪连接,并已添加到 “unconfirmed list” 中
- 或者报文属于已知且 “confirmed”(已确认)的跟踪连接,正在沿原始方向(= 第一个看到的报文的方向)流动,并且自第一个数据包以来,在回复方向上尚未看到任何数据包。
| 匹配此报文的 conntrack 表达式 | |
|---|---|
| Nftables | ct state new |
| Iptables | -m conntrack –ctstate NEW |
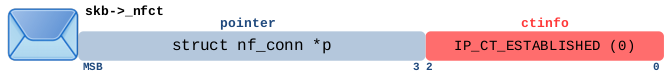
报文属于已跟踪连接且满足以下所有条件:
- 报文不是该连接看到的第一个报文
- 数据包沿原始方向流动(= 与该连接看到的第一个数据包的方向相同)
- 在此数据包之前,已在该连接的两个方向上看到数据包
| 匹配此报文的 conntrack 表达式 | |
|---|---|
| Nftables | ct state established |
| Nftables | ct state established ct direction original |
| Iptables | -m conntrack –ctstate ESTABLISHED |
| Iptables | -m conntrack –ctstate ESTABLISHED –ctdir ORIGINAL |
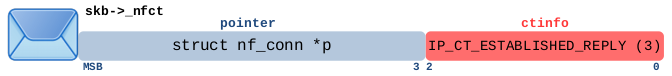
报文属于已跟踪连接且满足以下两个条件:
- 数据包不是该连接看到的第一个数据包
- 数据包沿回复方向流动(= 与该连接看到的第一个数据包的方向相反)
| 匹配此报文的 conntrack 表达式 | |
|---|---|
| Nftables | ct state established |
| Nftables | ct state established ct direction reply |
| Iptables | -m conntrack –ctstate ESTABLISHED |
| Iptables | -m conntrack –ctstate ESTABLISHED –ctdir REPLY |
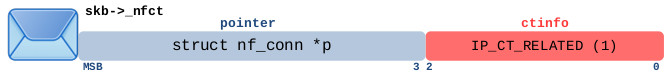
报文属于以下两种情况之一:
- 该数据包是有效的 ICMP 错误消息(例如 type=3 “destination unreachable”, code=0 “network unreachable”),与已跟踪的连接相关,报文沿着原始方向流动的,指针 *p 指向该连接。
- 该数据包是新连接的第一个数据包,但该连接与已跟踪的连接相关,或者换句话说,它是预期连接(请参见上面图 3.3 中的 IPS_EXPECTED 状态位)。例如,当您针对 FTP 协议使用 ct helper 程序时会发生这种情况。这是一个非常复杂的主题,值得专门写一篇博客文章。这里需要注意的是,只有属于预期连接的第一个数据包才标记有 IP_CT_RELATED。与任何其他跟踪连接一样,该连接的所有后续数据包都标有 IP_CT_ESTABLISHED 或 IP_CT_ESTABLISHED_REPLY。
| 匹配此报文的 conntrack 表达式 | |
|---|---|
| Nftables | ct state related |
| Nftables | ct state related ct direction original |
| Iptables | -m conntrack –ctstate RELATED |
| Iptables | -m conntrack –ctstate RELATED –ctdir ORIGINAL |
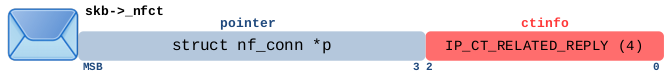
ct 系统对已跟踪连接的有效 ICMP 错误消息(type=3 “destination unreachable”, code=0 “network unreachable”)报文,进行以下设置。相对于该连接,它沿回复方向流动。指针 *p 指向该连接。然而,对于预期连接值 IP_CT_RELATED_REPLY 永远不会被设置。
| 匹配此报文的 conntrack 表达式 | |
|---|---|
| Nftables | ct state related |
| Nftables | ct state related ct direction reply |
| Iptables | -m conntrack –ctstate RELATED |
| Iptables | -m conntrack –ctstate RELATED –ctdir REPLY |

ct 系统为它认为无效的数据包,进行如下设置:
如果数据包在遍历 ct 主钩子函数时未通过有效性检查,则 ct 系统会认为该数据包“invalid”,并将指针和 ctinfo 设置为零。因此,该数据包不与任何跟踪的连接相关联。丢弃“无效”数据包不是 ct 系统的工作。但是,管理员可以使用以下匹配表达式创建防火墙规则来丢弃这些数据包:
| 匹配此报文的 conntrack 表达式 | |
|---|---|
| Nftables | ct state invalid |
| Iptables | -m conntrack –ctstate INVALID |

本节介绍一种通过命令标记网络数据包的方法,从而 ct 系统忽略该报文(= 报文保持不变并且不跟踪该报文)。与此表中描述的其他情况相比,当数据包遍历 ct 主钩子函数时,ctinfo 不会设置为此值(优先级 -200)。为了使该机制正常工作,必须已经在 ct 主钩子函数遍历之前的钩子函数中进行标记(优先级 < -200,例如 -300)。如果 ct 主钩子函数看到数据包的 ctinfo 已被设置为 IP_CT_UNTRACKED,该数据包将不变,并且不会对齐跟踪。 Nftables/Iptables 规则可以使用以下表达式来匹配这些数据包:
| 匹配此报文的 conntrack 表达式 | |
|---|---|
| Nftables | ct state untracked |
| Iptables | -m conntrack –ctstate UNTRACKED |
图 3.4:skb->_nfct 保存一个指针和 3 位整数 ctinfo。该表显示了所有可能的值并解释了它们的含义。
3.4 拓扑示例
在下面的部分中,我将展示一些示例,这些示例将演示如何在 ICMP、UDP 和 TCP 协议的情况下处理连接跟踪状态。所有这些示例都将基于图 3.5 中所示的网络拓扑:client host(IPv4 地址 192.168.1.2 与 server host(IPv4 地址 10.0.0.2)正在进行通信。路由器充当两台主机之间的下一跳,并执行连接跟踪和带状态的报文过滤。图 3.5 显示了 Netfilter IPv4 的三个 hook 点:Prerouting、Forward 和 Postrouting,在本例中,路由器上的网络数据包将遍历这些钩子。ct 系统已加载,因此 ct main 钩子函数(优先级为 -200)注册到 Prerouting hook 点,ct help+confirm 钩子函数(优先级为 MAX)注册到 Postrouting hook 点。此外,Nftables 基础链(优先级 0)注册到 Forward hook 点,这将其放在两个 ct hook 函数之间。
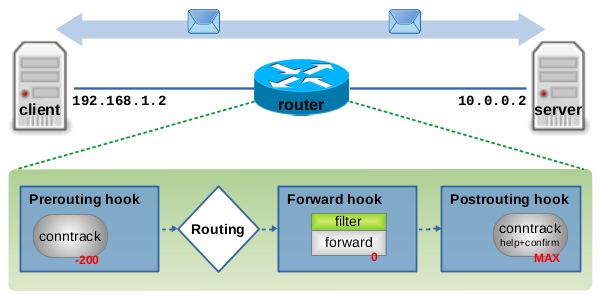
图 3.5:示例拓扑:客户端和服务器作为通信的端点,路由器作为中间下一跳,执行连接跟踪和带状态数据包过滤。
在示例中仅展示正常的协议交互(例如 ICMP ping、TCP 握手等)的情况下的连接跟踪状态变化。所有报文都会及时发送,跟踪的连接不会存在超时情况。
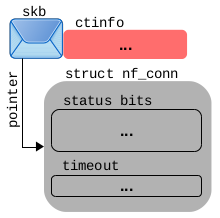
图 3.6:skb 都附加一个跟踪连接实例,显示 ctinfo、status 和 timeout。
如图 3.6 所示,一个网络数据包正在遍历路由器上的钩子函数,该 skb 上的 ctinfo 变量以及附加的跟踪连接实例及其 status 和 timeout 变量。如果 ctinfo、status bit 位或 timeout 值在下面的示例中以粗体显示,则表示该值/ bit 位此时正在被修改。如果字体非粗体显示,则这意味着该值/ bit 位在过去已经被设置并且保持不变。
3.5 ICMP 示例
此示例演示了在 ICMP ping 的跟踪连接的状态变化,如图 3.7 所示。client 向 server 发送单个 ICMP echo-request 请求,server 以 ICMP echo-reply 进行应答。
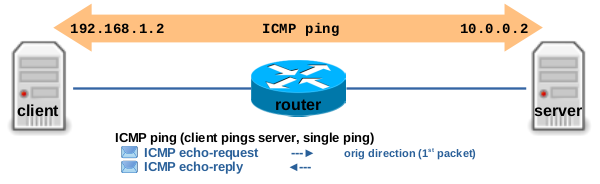
图 3.7 client pings server, client:~$ ping -c1 10.0.0.2.
尽管 icmp 不是面向连接的协议,但 ct 系统根据:源+目的 IP、ICMP type、code 和 id 将其视为单个连接跟踪。图 3.8 显示了两个网络数据包穿过 ct 钩子函数和路由器上的 Nftables 链时的情况。 ICMP echo-request 报文会导致创建新的跟踪连接,ctinfo 被设置为 IP_CT_NEW。与此数据包匹配的 Nftables ct 表达式将为 ct state new。一旦数据包到达 ct help + confirm 钩子函数,status 被设置为 IPS_CONFIRMED bit 位,timeout 设置为 30 秒,并且所跟踪的连接将被添加到 central ct 表中。在此示例中,相应的 ICMP echo-reply 在 30s 超时时间到期之前就已经送达。ct 系统检测到它属于同一跟踪连接,将 ctinfo 设置为 IP_CT_ESTABLISHED_REPLY,设置 status IP_CT_SEEN_REPLY bit 位,并将 timeout 重新更新为 30 秒。与此数据包匹配的 Nftables ct 表达式为 ct state established。一旦 30 秒超时时间到期,ct 垃圾回收就会设置 status IPS_DYING bit 位,从 central ct 表中移除跟踪的连接,将其添加到 dying list 中,并最终将其删除。
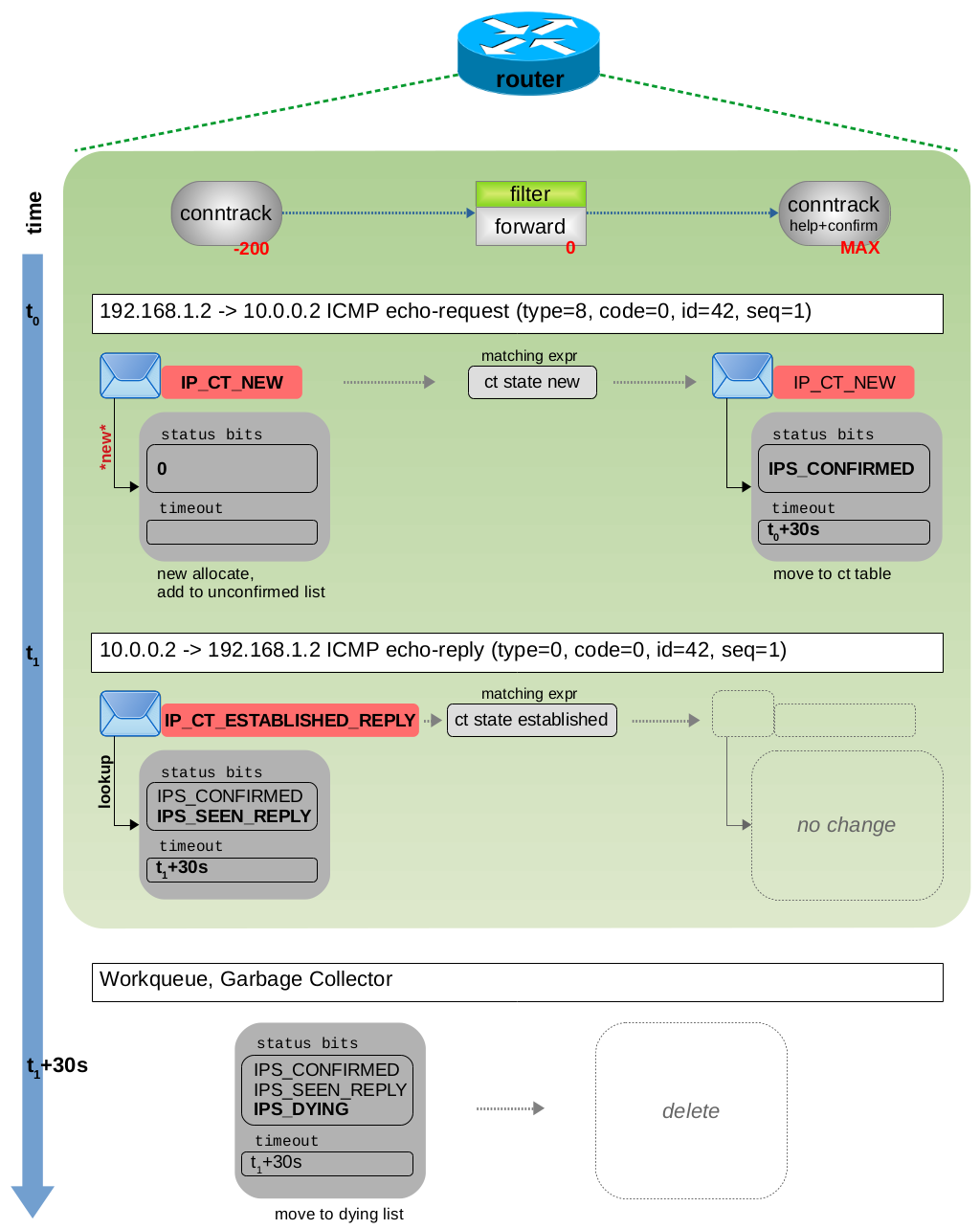
图 3.8:ICMP echo-request 和 echo-reply 遍历 ct hook 函数
如果 client 使用命令 ping 10.0.0.2 向 server 发送连续的 ICMP echo-requests 报文(默认间隔为 1 秒),则所有这些数据包中将包含相同的 ICMP id(图 3.8 的示例中 id = 42),但对于每个 echo-request/reply 对的 ICMP 序列号将递增 1。 ct 系统会将所有这些数据包分配给同一个跟踪的连接,并且只要 ICMP echo-requests/reply 报文不断,该连接就不会超时。在内部,ct 通过记住其元组中的 id 值来实现这一点;代码请参阅 icmp_pkt_to_tuple() 函数。
3.6 UDP 示例
如图 3.9 所示,此示例演示了在 DNS query + response 的情况下跟踪连接的状态变化。client 向 server 发送一条 DNS query 消息,请求 A 记录( google.com 域名对应的 IPv4 地址)。这会导致包含 DNS query 的 UDP 数据包从 client 发送到 server 主机目标端口 53 上,并导致从 server 回应 client 一个包含 DNS response 的 UDP 数据包。
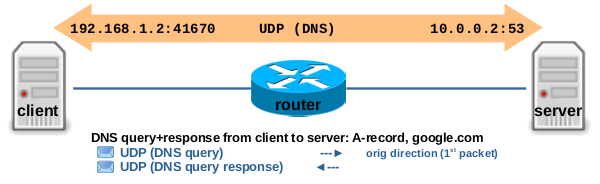
图 3.9:client 从 DNS server 查询 google.com 域名的 A 记录,client:~$ host -t A google.com
UDP 不是面向连接的协议,但是 ct 系统根据:源 + 目的 ip 地址、源+目的 UDP 端口,将其视为单个跟踪连接。图 3.10 显示了两个网络数据包穿过 ct 钩子函数和路由器上的 Nftables 链时的情况。包含 DNS query 的 UDP 数据包会导致创建新的跟踪连接。 ctinfo 被设置为 IP_CT_NEW。与此数据包匹配的 Nftables ct 表达式为:ct state new。一旦数据包到达 ct help + confirm 钩子函数,status 会设置 IPS_CONFIRMED bit 位,timeout 设置为 30 秒,并且所跟踪的连接将被添加到 central ct 表中。在此示例中,包含 DNS response 的 UDP 数据包在 30 秒超时时间到期之前进行回复。ct 系统检测到它属于同一跟踪连接,将 ctinfo 设置为 IP_CT_ESTABLISHED_REPLY,设置 status IP_CT_SEEN_REPLY bit 位并将 timeout 重新更新 30 秒。与此数据包匹配的 Nftables ct 表达式为:ct state established。一旦 30 秒超时到期,ct 垃圾回收就会设置status IPS_DYING bit 位,从 central ct 表中删除跟踪的连接,将其添加到 dying list 中,并最终将其删除。
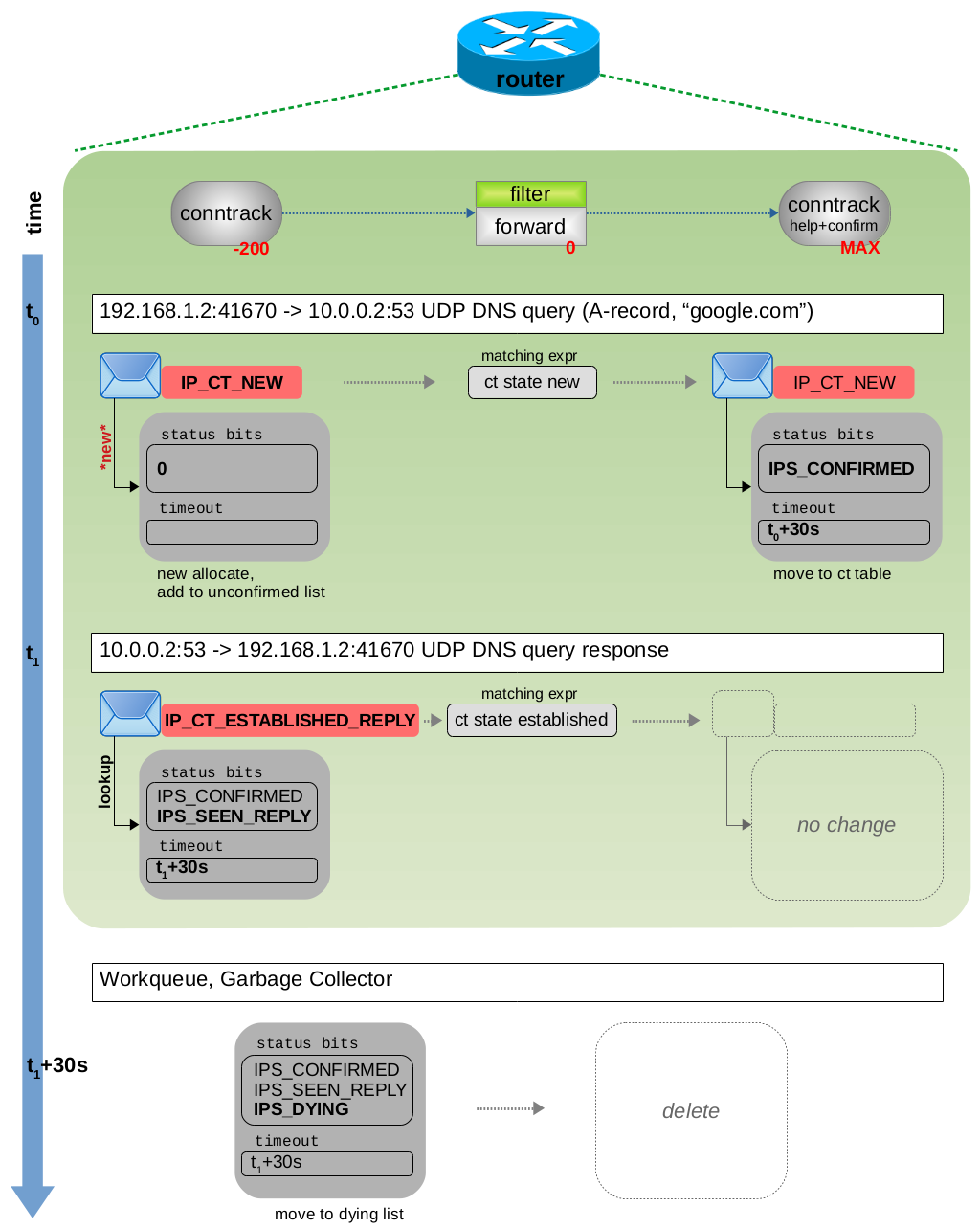
图 3.10: DNS query 与 DNS response 遍历 ct 钩子函数
如果继续收到来自相同的源和目的 IP 地址以及 UDP 端口 的 UDP 数据包(无论哪个方向),那么 ct 系统都会将所有这些 UDP 数据包分配给同一个跟踪的连接,并且只要 UDP 报文不断,该连接就不会超时。在这种情况下,一旦看到属于该连接的第三个数据包,status 将被设置 IPS_ASSURED bit 位。常见的命令行工具(例如 host)在域名解析时通常不仅仅需要 A 记录。一般情况下,主机会请求 A 记录、AAAA 记录和 MX 记录。Host 会对每种 DNS 查询使用不同的 socket 套接字(= 另一个 UDP 源端口号),这导致 ct 系统将每种查询视为一个新的跟踪连接。
3.7 TCP 状态
使用 conntrack 工具列出跟踪的 TCP 连接:
$ conntrack -L
udp 17 3 src=192.168.49.1 ...
tcp 6 21 TIME_WAIT src=192.168.2.100 ...
tcp 6 360313 ESTABLISHED src=192.168.2.100 ...
# ^
# TCP state ???
如果您已阅读 RFC 793 或熟悉 TCP 状态机,那么您就会在 conntrack 工具输出中识别出 TCP 的状态,例如 TIME_WAIT 和 ESTABLISHED。由于 ct 系统只是中间的透明观测者,无法访问通信端点的 TCP 套接字(在大多数情况下,这些套接字位于 ct 系统之外的其他主机上)。因此,您在输出中看到的那些状态并不是端点的真实 TCP 状态。
然而,ct 系统对报文的 4 层信息进行了详细分析,它基于观察到的网络数据包,能够对当前 TCP 状态进行推测。当 TCP 数据包遍历其中一个主要 ct 钩子函数时,nf_conntrack_tcp_packet() 函数会分析数据包的 TCP 部分。在本的第二章,我提到 struct nf_conn 有一个 union nf_conntrack_proto proto 成员变量,用于跟踪 4 层协议的详细信息。对于 TCP,该 union 包含 struct ip_ct_tcp 结构。除此之外,它还包含 uint8_t state 变量,用于跟踪猜测的 TCP 状态。
tcp_conntrack_names[] 字符串数组包含所有可能状态的文本表示:SYN_SENT、SYN_RECV、ESTABLISHED、FIN_WAIT、CLOSE_WAIT、LAST_ACK、TIME_WAIT、CLOSE 和 SYN_SENT2。该数组内容就是您通过 conntrack -L 输出中看到的内容。但这与 ctinfo 和 status 又有何关系? ct 系统分析 TCP 状态、序列号、接收窗口、重传等,因此它在某些情况下将数据包视为“invalid”,例如,当它看到序列号不对时,然后通过设置 skb->_nfct=NULL 将这些数据包分类为无效报文。
ct 系统可识别 TCP 3 次握手、TCP FIN 连接终止等,并据此动态的设置跟踪的连接的 timeout 超时时间。当它识别出 TCP 3 次握手成功完成时,它会将 status 设置为 IPS_ASSURED bit 位。总结一下:连接跟踪的 TCP 状态是一个单独的变量,ct 系统对 TCP 报文进行分析会影响 ctinfo 和 status 变量的值。
因此,当您在 conntrack -L 的输出中看到 ESTABLISHED 时,这并不是 Nftables 表达式:ct state established 要匹配的内容。ct 系统一旦看到双向流量,ct 系统不会等待真正的 TCP 握手完成,就认为 ct 跟踪的连接 established。当它看到第一个有效的回复数据包(通常是 TCP SYN ACK)时,它会将 ctinfo 设置为 IP_CT_ESTABLISHED_REPLY。
事情必须是这样做,否则常用的带有 conntrack 表达式的 Nftables 规则(如:以下链中带有 policy drop 的两个规则)将无法按预期工作:
# allowing new connections to be established from eth0 to eth1,
# but only established+related packets allowed from eth1 to eth0
table ip filter {
chain forward {
type filter hook forward priority filter; policy drop;
iif eth0 oif eth1 ct state new,established,related accept
iif eth1 oif eth0 ct state established,related accept
}
}
Nftables ct state established或 Iptables -m conntrack --ctstate ESTABLISHED 这样的 conntrack 表达式,并不是真正的 TCP 状态中的 ESTABLISHED。
3.7 TCP 示例
此示例演示了 ct 系统如何跟踪 TCP 连接,如图 3.11 所示,TCP 3 次握手之后,发送一些有效负载数据,并以正常连接终止结束会话。client 打开到 server 的连接(例如到 TCP 目的端口 80/HTTP),发送一些有效负载数据,然后以普通方式关闭连接。
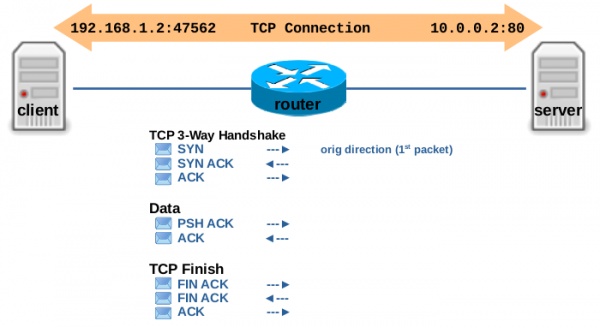
图 3.11:client 和 server 之间的 TCP 连接示例
ct 系统根据:源+目的 IP 地址和源+目的 TCP 端口,作为单个跟踪连接进行处理。此外,它还会分析每个报文的 4 层信息。图 3.12 显示了 TCP 3 次握手期间的状态和 timeout 超时时间变化,图 3.13 和 3.14 显示了有效负载数据传输情和 TCP 连接终止情况。您可以看到,ct 系统根据对当前 TCP 状态信息动态设置 timeout 超时时间。例如,在 3 次握手期间或等待 TCP ACK 时,ct 选择一个较短的超时时间。但是,如果 3 次握手已成功完成,TCP 连接现已完全建立,并且当前没有未完成的 TCP ACK,则 ct 选择较长的超时时间。然后它还会将 status 设置为 IPS_ASSURED bit 位。当然,大多数 TCP 连接会交换更多的有效负载数据,并且它们是双向进行通信的,从而导致交换的数据包比图 3.13 中所示的多得多。但是,连接跟踪状态变量的值与图 3.13 中所示的值没有任何不同。
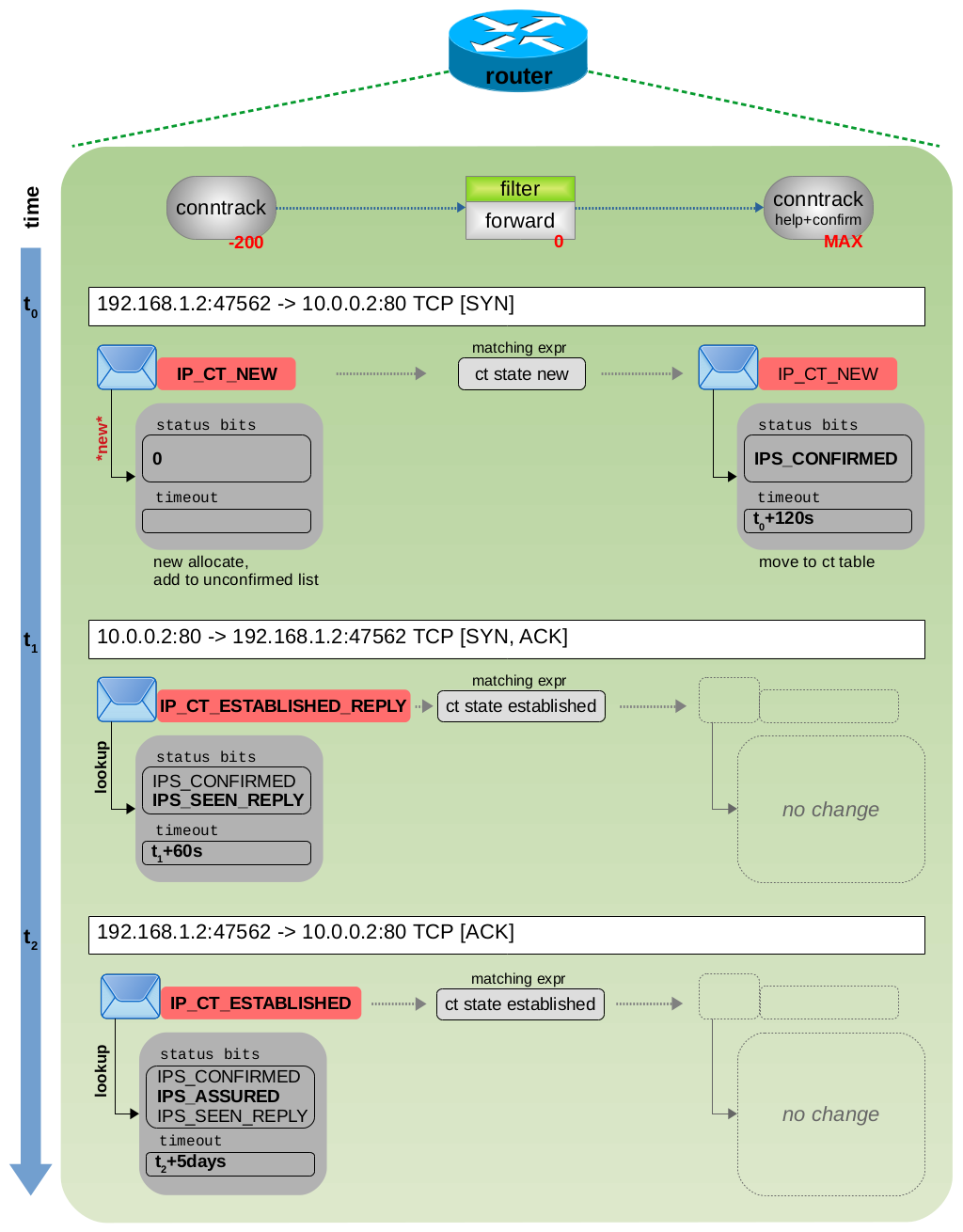
图 3.12:TCP 3 次握手
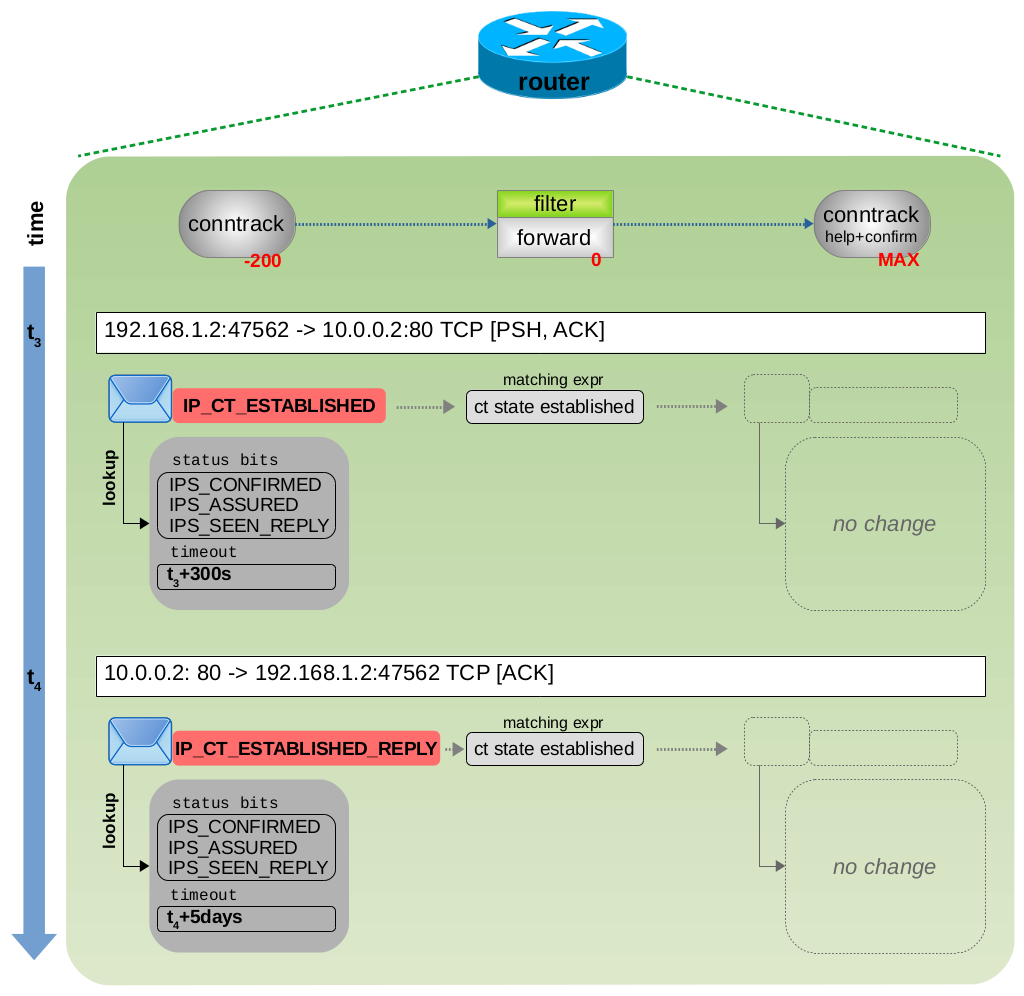
图 3.13:TCP 有效负载传输
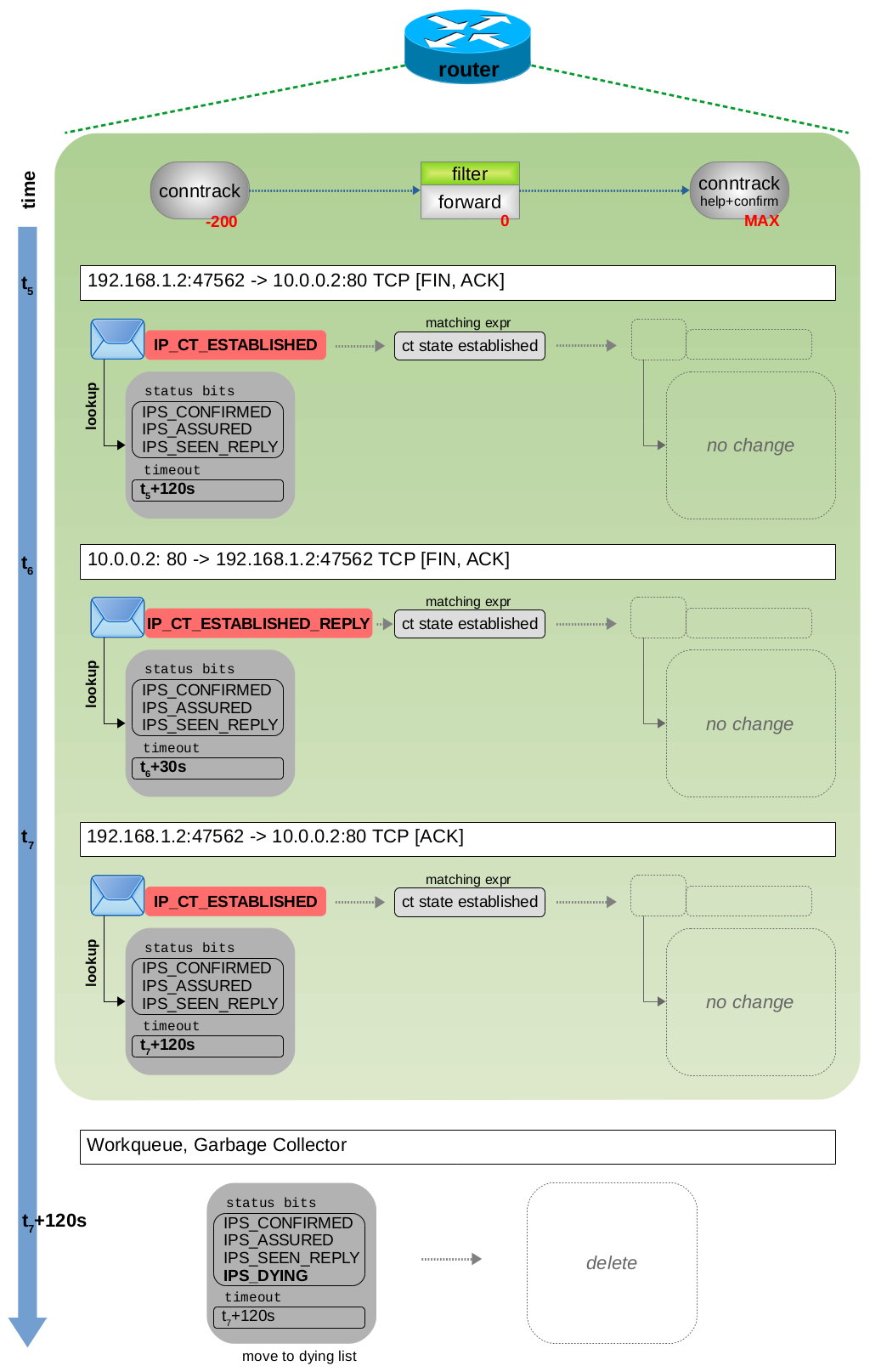
图 3.14:TCP连接终止
参考
- Connection tracking (conntrack) - Part 1: Modules and Hooks
- Connection tracking (conntrack) - Part 2: Core Implementation
- Connection tracking (conntrack) - Part 3: State and Examples
公众号:Flowlet

「如果这篇文章对你有用,请随意打赏」
 ZhangShuai's Blog
ZhangShuai's Blog
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付

comments powered by Disqus