关于作者
张帅,网络从业人员,公众号:Flowlet
个人博客:https://flowlet.net/
前言
2018 年 9 月 1 日,Bilgin Ibryam 在 InfoQ 发表了一篇名为 Microservices in a Post-Kubernetes Era 的文章。
文中虽然没有明确指明“后 Kubernetes 时代的微服务”是什么,但是从文中可以看出作者的观点是:在后 Kubernetes 时代,服务网格(Service Mesh)技术已完全取代了通过使用软件库来实现网络运维的方式。
服务网格(Service Mesh)因此也被成为下一代微服务技术,笔者将会从技术演进的角度阐述一下,Service Mesh 的过去、现在与未来。
1. 计算机互联畅想时代
在 Intenet 实现计算机互联之前,最开始人们想象的计算机之间服务的交互方式是这样的:
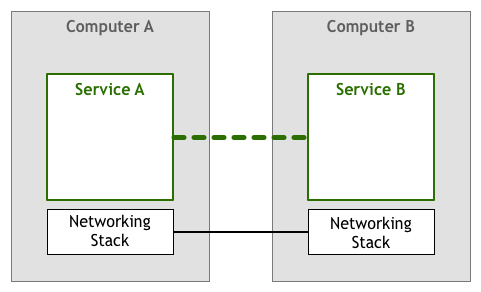
一个应用程序通过与另一个应用程序发生对话来完成用户的请求。
2. ARPANET 时代
1961 年 10 月,苏联成功发射 R-16 洲际导弹,这意味着美国本土将面临远程导弹打击的威胁。
为了保证美国能够在核打击下具备一定的生存反击能力,美国国防部授权 APRA(Advanced Research Project Agency,美国国防部高级研究计划局) 建立一个可经受敌军打击的“分布式”军用指挥系统,并将其命名为 ARPANET(阿帕网)。
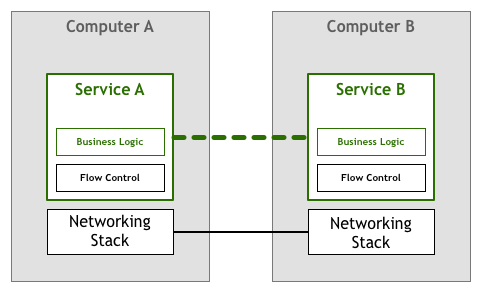
在 TCP/IP 协议出现之前,计算机很稀有,也很昂贵,计算机之间的互联的需求不大,数据量也很有限。
因此都是需要应用程序自己来处理网络通信所面临的丢包、乱序、重试等一系列流控问题,因此在应用程序的实现中,除了业务逻辑外,还包含对网络传输问题的处理逻辑。
3. TCP/IP 时代
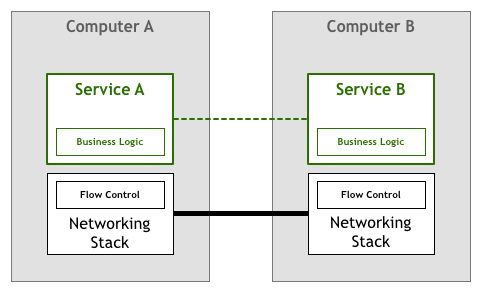
随着计算机变得越来越普及,计算机之间的连接数量和数据量出现了爆炸式的增长。
为了避免每个应用程序都需要自己实现一套相似的网络传输处理逻辑,将应用程序中通用的路由传输与流量控制逻辑抽离出来,并将其作为操作系统网络层的一部分,后续逐渐形成 TCP/IP 这类的标准协议规范。
4. 微服务 1.0 时代
在 TCP/IP 协议出现之后,机器之间的网络通信不再是一个难题。当时服务都是以单体架构(monolithic)的形式运行,所有的业务进程都运行在一台服务器上。
各个业务进程之间紧密耦合,如果一台服务器上的某个业务进程遇到需求峰值,纵使这台服务器上的其他业务进程资源利用率还比较低,也必须对整台服务器做集群扩展。
而且由于各个业务进程紧密耦合,单个业务进程故障会对服务器上的其他业务进程造成故障影响。
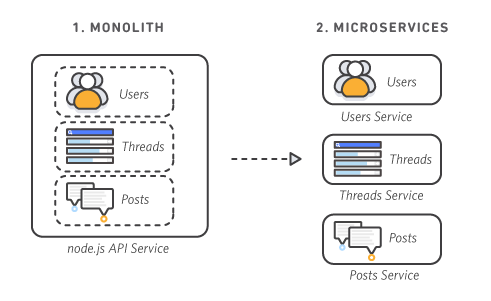
为了解决单体架构(monolithic)的缺陷,在 2014 年 Martin Fowler 与 James Lewis 合写的文章《Microservices: A Definition of This New Architectural Term》中首次了解到微服务的概念。
在微服务架构(Microservices)中,每个业务进程作为一项服务运行。这些服务之间使用轻量级 API 通过明确定义的接口进行通信。这些服务围绕业务功能进行构建,每项服务只执行一项特定功能。由于各个服务之间独立运行,因此可以针对各项服务独立进行更新、部署和扩展,以满足客户对不同业务服务的特定功能的需求。
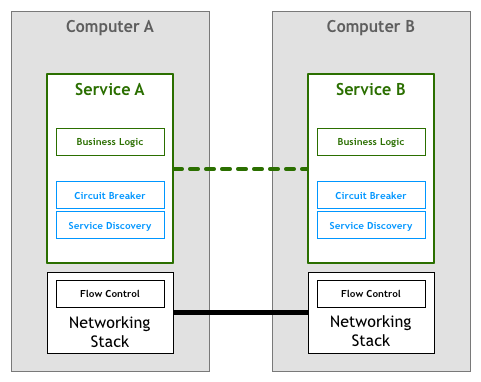
在微服务这样的分布式系统中,最主要的是要有能提供服务发现的能力:即找到有能力处理请求的服务实例。比如,有个叫作 Teams 的服务需要找到一个叫作 Players 的服务实例。通过调用服务发现,可以获得一个满足条件的服务器清单。
除此之外在分布式系统中的每个服务都需要根据业务需求来实现诸如:熔断策略、负载均衡、认证和授权、quota 限制、trace 和监控等一系列与业务无关的通用功能逻辑。
5. 微服务 2.0 时代
为了避免分布式系统中每个服务都需要自己实现一套与业务无关的通用功能逻辑,随着技术的发展,一些面向微服务架构的开发框架出现了,如 Twitter 的 Finagle、Facebook 的 Proxygen 以及 Spring Cloud 等等。
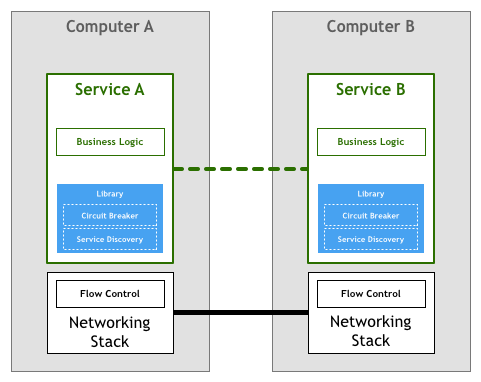
这些框架实现了分布式系统通信需要的各种与业务无关的功能逻辑:如负载均衡和服务发现等,这在一定程度上屏蔽了这些通信细节,使得开发人员可以专注于业务逻辑,而无需关注各种底层实现。
6. Service Mesh 1.0 时代
第二代微服务模式看似完美,但开发人员很快又发现,它也存在一些本质问题:
- 虽然框架本身屏蔽了分布式系统通信的一些通用功能实现细节,但在实际应用中,开发者去追踪和解决框架出现的问题也绝非易事;
- 微服务软件库开发框架通常只支持一种或几种特定的语言;那些用没有框架支持的语言编写的服务,很难融入面向微服务的架构体系;
- 框架以 lib 库的形式和服务联编,库版本兼容问题非常棘手;同时,框架库的升级也无法对服务透明,服务会因为和业务无关的 lib 库升级而被迫升级;
因此与 TCP/IP 协议栈一样,我们急切地希望能够将分布式服务所需要的一些特性放到底层的平台中。人们基于 HTTP 协议开发非常复杂的应用,无需关心底层 TCP 如何控制数据包。在开发微服务时也是类似的,工程师们聚焦在业务逻辑上,不需要浪费时间去编写服务基础设施代码或管理系统用到的软件库和框架。
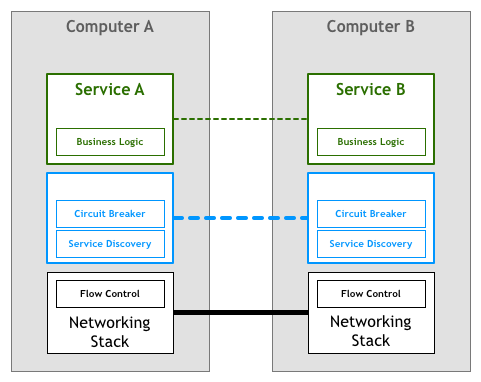
但这在当时,内核可编程技术(ebpf)还不成熟,直接在内核网络协议栈中加入这样的一个业务层不仅对内核有侵入性,而且由于内核更新速度太慢,无法满足快速变化的业务需求。
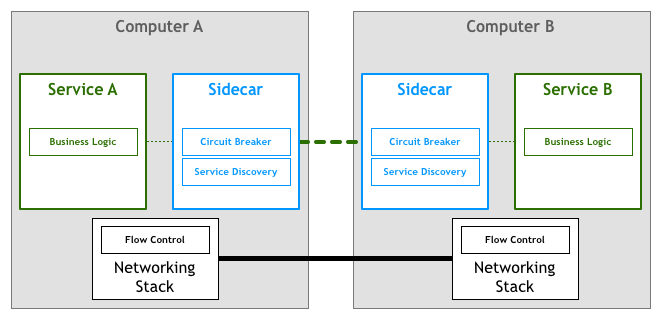
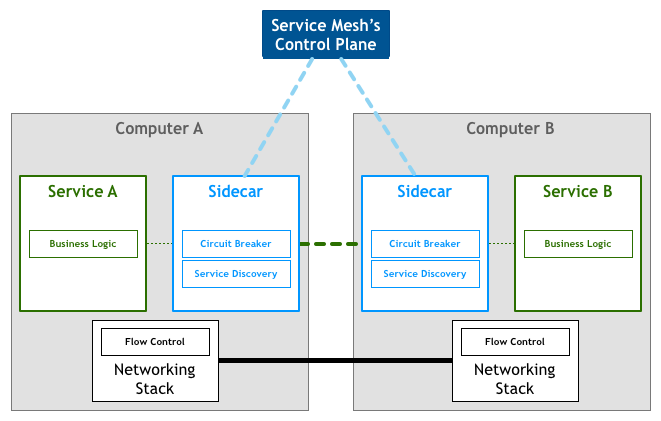
因此以 Linkerd,Envoy,Nginx Mesh 为代表的 Sidecar(边车模式)应运而生,这就是第一代 Service Mesh,它将分布式服务通信所需要的负载均衡、服务发现、认证授权、监控追踪、流量控制等功能,部署到一个单独的进程或容器中。Sidecar 作为一个和服务对等的代理服务,和服务部署在一起,接管服务的流量,通过 Sidecar 之间的通信间接完成服务之间的通信请求,从而解决上述三个问题。
如果我们从一个全局视角来看,就会得到如下部署图:
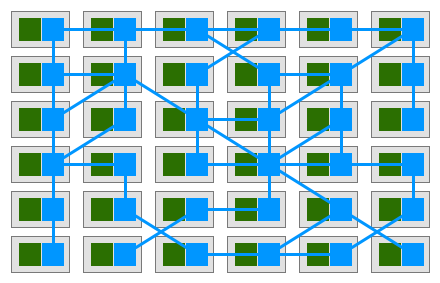
如果我们暂时略去服务,只看 Service Mesh 的单机组件组成的网络:
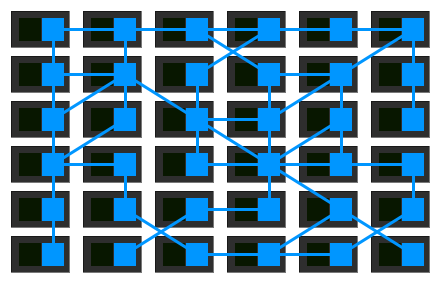
由此大家可以看出所谓的服务网格(Service Mesh),就是一个由若干服务代理所组成的错综复杂的网格。
7. Service Mesh 2.0 时代
第一代 Service Mesh 由一系列独立运行的单机代理服务构成,随着容器技术的发展,微服务开始部署到更为复杂的运行时(如 Kubernetes 和 Mesos)上,并开始使用这些平台提供的网格网络工具。
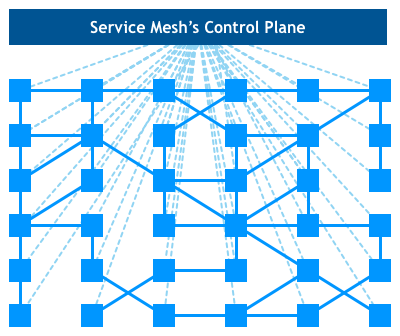
服务网格正从使用一系列独立运行的代理转向使用集中式的控制面板。
所有的单机代理组件通过和控制面板交互进行网络拓扑策略的更新和单机数据的汇报,这就是以 Istio 为代表的第二代 Service Mesh。
如果只看单机代理组件(数据面板)和控制面板的 Service Mesh 全局部署视图如下:
8. Service Mesh 的未来
对于 Service Mesh 而言,目前最流行框架是 Istio,而它的数据面是 Envoy(使用 c++ 14 开发)。
基于 Istio 的 Service Mesh 架构在互联网公司进行大规模线上部署的时候逐渐遇到以下问题:
- Envoy(基于 c++ 开发) 上手难度大、维护成本高;
- Sidecar 带来的额外资源开销以及 Proxy 模式带来的延迟增加;
- xDS 全量下发带来内存消耗过大;配置文件过多难以查看运维的问题;
- 微服务之间的通过 http 或者其他不安全的协议进行通信,然而东西向流量难以进行防护;
- 线上为了保证系统的可用性,通常多集群多活部署,开源的 Service Mesh 方案只注重单集群内的治理,对多集群多活场景没有直接给出完善的解决方案;
下面我们就从以上痛点出发,主要从 Envoy上手难、Sidecar 额外开销与延迟问题、xDS 全量下发三方面,浅析一下 Service Mesh 的未来演进方向。
关于东西向流量防护与多集群治理的问题由于篇幅有限本次暂不涉及。
8.1 Envoy 上手难度大、维护成本高问题解决方案
针对 Envoy 上手难度大、维护成本高的问题,主要有两种解决方案:
- 对 Envoy 数据面通过其他易上手的语言(如:go)进行重写替换;
- 通过其他语言编写的插件增加 Envoy 的特性与可维护性;
8.1.1 Envoy 替换
对于 Service Mesh 而言,目前最流行框架是 Istio,而它的数据面是 Envoy(使用 c++ 14 开发)。
Envoy 入门门槛比较高,直接改动或者进行二次开发难度很大。除此之外,很多公司更希望建立自己的生态系统。

针对这个问题蚂蚁集团直接通过 Go 语言开发自研产品 MOSN(Modular Open Smart Network)进行替代,并经过双 11 大促几十万容器的生产级验证。
8.1.2 插件模式
WebAssembly(WASM),是一个二进制指令集,最初是跑在浏览器上来解决 JavaScript 的性能问题,但由于它良好的安全性,隔离性以及语言无关性等优秀特性,很快人们便开始让它跑在浏览器之外的地方,随着 WASI 定义的出现,只需要一个 WASM runtime,就可以让 WASM 文件随处执行。
Wasm 运行时可以以近似原生性能安全地隔离和执行用户空间代码,Envoy Proxy 率先使用 Wasm 作为扩展机制作为对数据平面的编程。
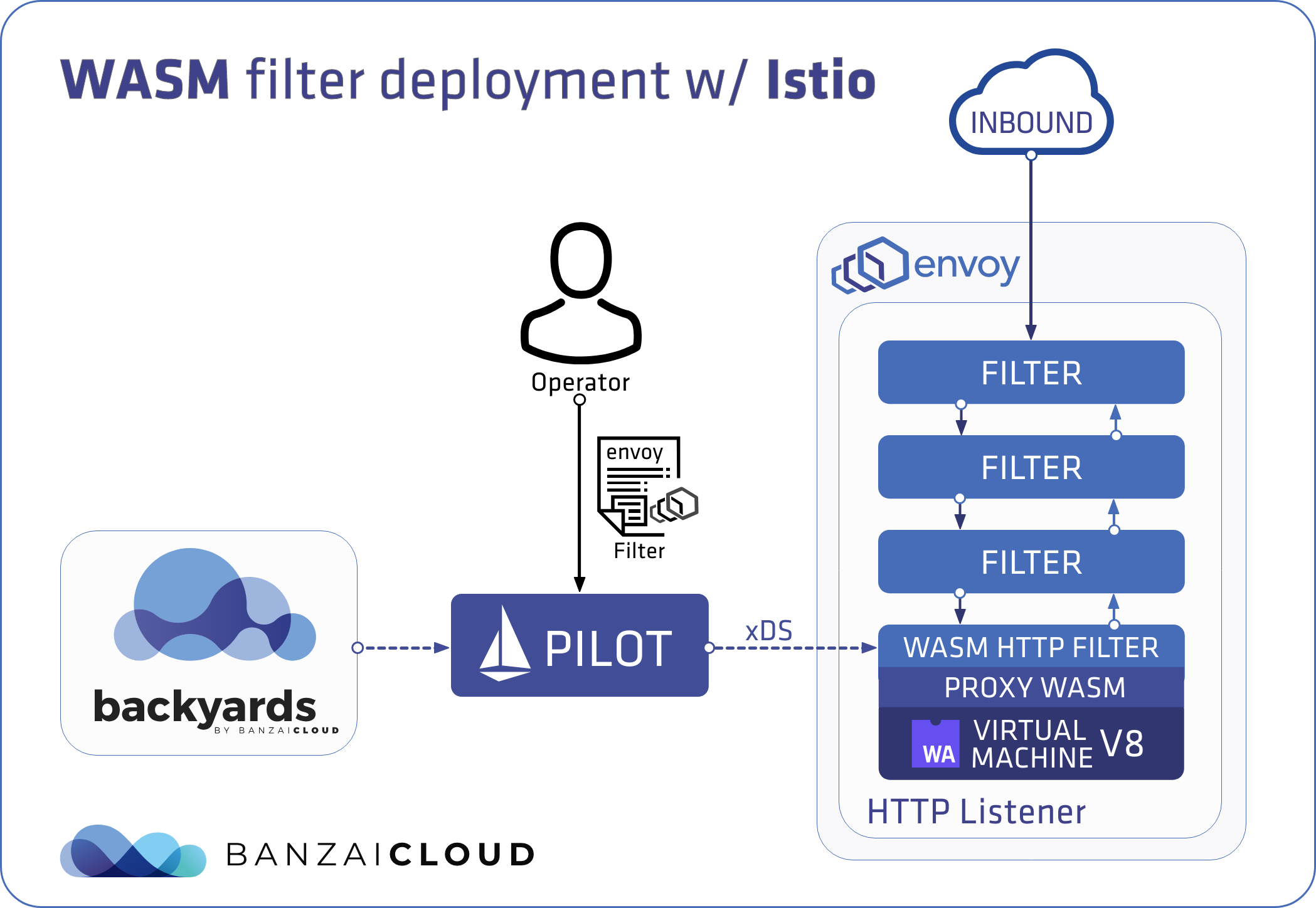
开发人员可以用 C、C++、Rust、AssemblyScript、Swift 和 TinyGO 等语言编写应用程序特定的代理逻辑,并将模块编译为 Wasm。
通过 proxy-Wasm 标准,代理可以在例如 Wasmtime 和 WasmEdge 的高性能运行时执行这些 Wasm 插件。目前,Envoy 代理、Istio 代理、MOSN 和 OpenResty 支持 proxy-Wasm。
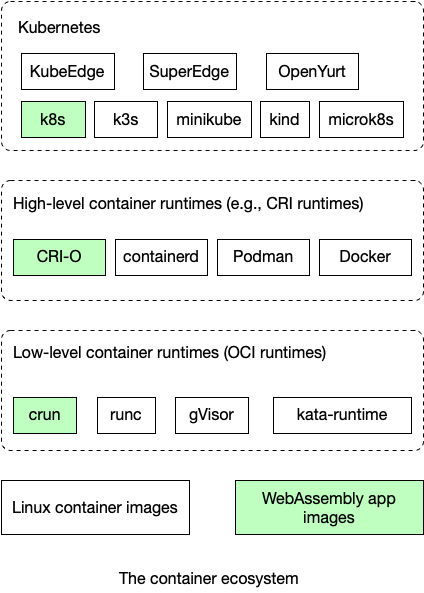
Wasm 可以充当通用应用程序容器。它在服务网格数据平面上的应用不仅限于边车代理。附加到边车的微服务也可以运行在轻量级 Wasm 运行时中。WasmEdge WebAssembly 运行时是一个安全、轻量级、快速、便携式和多语言运行时,Kubernetes 可以直接将其作为容器进行管理。
由于目前社区的 Wasm 方式不够成熟,除了 Wasm 外还有以下比较成熟的插件模式:
-
基于 Native c++ 自研,这类插件对研发人员要求过高,同时也是性能最高、结合性最好的。
-
以 lua, node.js 为代表的通过脚本方式实现插件的模式。
-
以蚂蚁为代表的通过 cgo 方式实现 filter 插件的模式。
-
基于 envoy filter 进行协议对接,通过外围产品来辅助完成的模式。
8.2 性能问题的解决方案
Envoy 作为 Sidecar 其提供的核心功能可以简单总结为以下三点:
- 对业务透明的请求拦截。
- 对拦截请求基于一定规则做校验、认证、统计、流量调度、路由等。
- 将请求转发出去,在 Service Mesh 中所有的流量出入都要经过 Sidecar,Sidecar 的加入增加了业务请求的链路长度,必然会带来性能的损耗。
在上述三点中,其中第 1、3 点是与业务基本无关的,属于通用型功能,而第 2 点的性能是与业务复杂度呈现相关性的,比如请求校验规则的多与少、遥测数据的采集精细度、数据统计的维度多样性等。
因此最有可能提升 Sidecar 性能的点就是高效的处理对请求的拦截与增加 Sidecar 之间通讯协议的高效性。
8.2.1 高效转发
针对请求的拦截,目前常规的做法是使用 iptables,在部署 Sidecar 时配置好 iptables 的拦截规则,当请求来临后 iptables 会从规则表中从上至下顺序查找匹配规则,如果没遇到匹配的规则,就一条一条往下执行,如果遇到匹配的规则,那就执行本规则并根据本规则的动作(accept, reject, log等),决定下一步执行的情况。

了解 iptables 的基本流程后,不难发现其性能瓶颈主要是两点:
- 在规则配置较多时,由于其本身顺序执行的特性,性能会严重下滑。
- 每个 request 的处理都要经过内核态 -> 用户态 -> 内核态的过程;当网络中有大量数据包到达内核时,会产生频繁的硬件中断、上下文切换;此外数据从内核态拷贝到用户态的,再拷贝到内核态的也会带来高额的性能损耗。
针对以上两点性能瓶颈,Linux 社区与 Envoy 社区通过以下方式进行优化:
- Linux 内核社区发布了 bpfilter,一个使用 Linux BPF 提供的高性能网络过滤内核模块,计划用来替代 netfilter 作为 iptables 的内核底层实现,实现 Linux 网络包过滤框架从 netfilter 向 BPF 过渡的演进。
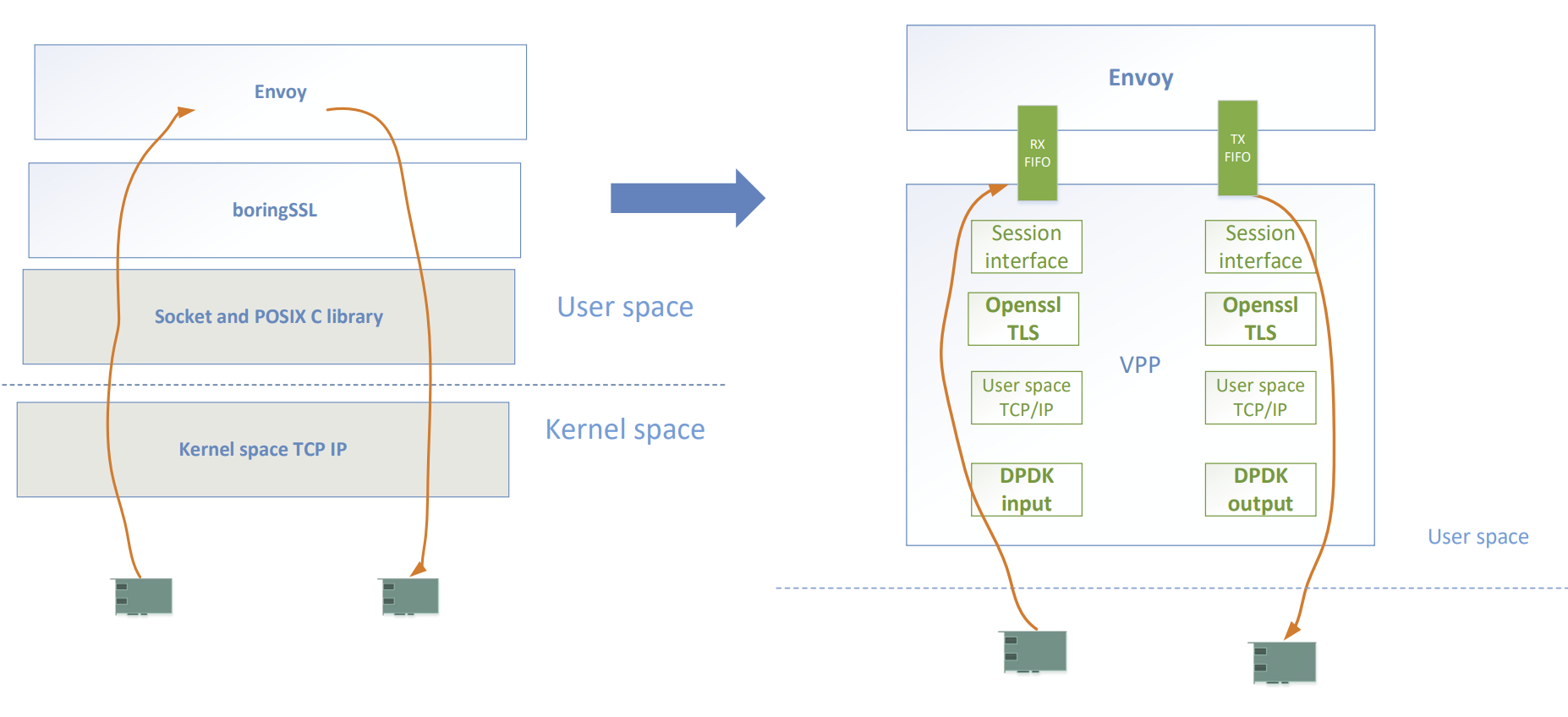
- Envoy 社区目前正在推动官方重构其架构,目的是为了支持用户自定义的 network socket 实现,最终目的是为了添加对 VPP(Vector Packet Processing) 扩展支持。
无论使用 VPP 或 Cilium(ebpf) 都可以实现数据包在纯用户态或者纯内核态的处理,避免内存的来回拷贝、上下文切换,且可以绕过 Linux 协议栈,以提高报文转发效率,进而达到提升请求拦截效率的目的。
8.2.2 高效通信
目前服务之前最常用的通信协议就是 http/https,不管是 HTTP1.0/1.1 还是 HTTPS,HTTP2,都使用了 TCP 进行传输。HTTPS 和 HTTP2 还需要使用 TLS 协议来进行安全传输。
这就出现了两个握手延迟:
- TCP 三次握手导致的 TCP 连接建立的延迟。
- TLS 完全握手需要至少 2 个 RTT 才能建立,简化握手需要 1 个 RTT 的握手延迟。
对于很多短连接场景,这样的握手延迟影响很大,且无法消除。除此之外还有队头阻塞的问题:
- TCP 队头阻塞主要是由 TCP 协议的可靠性机制引入的,TCP 使用序列号来标识数据的顺序,数据必须按照顺序处理,如果前面的数据丢失,后面的数据就算到达了也不会通知应用层来处理。
- TLS 队头阻塞主要是因为 TLS 协议都是按照 record 来处理数据的,如果一个 record 中丢失了数据,也会导致整个 record 无法正确处理。
概括来讲,TCP 和 TLS1.2 之前的协议存在着结构性的问题,如果继续在现有的 TCP、TLS 协议之上实现一个全新的应用层协议,以上提到的问题将始终无法得到有效解决。
在这种背景下谷歌公司开发了一种基于用户数据报协议(UDP)的传输层协议 QUIC(Quick UDP Internet Connections),旨在提高网络连接的速度和可靠性,以取代当前互联网基础设施中广泛使用的传输控制协议(TCP)。
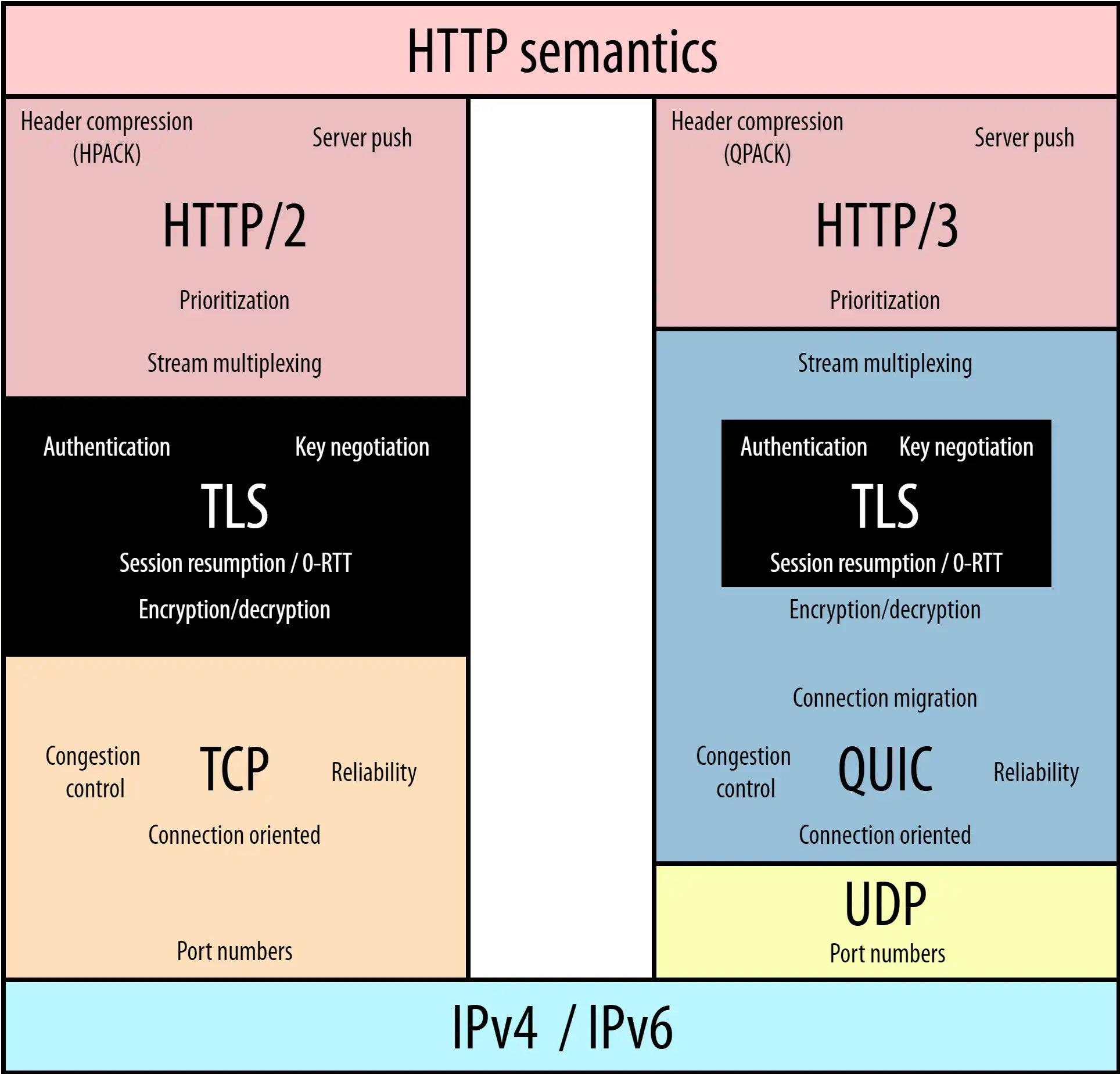
因为 UDP 本身没有连接的概念,不需要三次握手,优化了连接建立的握手延迟,同时在应用程序层面实现了 TCP 的可靠性,TLS 的安全性和 HTTP2 的并发性,只需要用户端和服务端的应用程序支持 QUIC 协议即可,完全避开了操作系统和中间设备的限制,便于复用已有的网络设施。
QUIC 通过加密和多路复用技术来提供更高的安全性和更快的数据传输。它支持在单个连接上并行发送多个数据流,从而降低延迟并提高吞吐量。QUIC 还具有拥塞控制和流量控制等机制,以应对网络拥塞并保证数据传输的稳定性。使用 QUIC 后具体的提升效果在 Google 旗下的 YouTube 已经得到验证。
Envoy 社区正在推动官方重构,最终目的是希望使用 QUIC 作为 Sidecar 之间的通讯协议。
8.4 xDS 全量下发解决方案
xDS 协议是 “X Discovery Service” 的简写,这里的 “X” 表示它不是指具体的某个协议,是一组基于不同数据源的服务发现协议的总称,包括 ADS(Aggregated Discovery Service)、SDS(Service Discovery Service)、EDS(Endpoint Discovery Service)、CDS(Cluster Discovery Service)、RDS(Route Discovery Service)、LDS(Listener Discovery Service)等。
客户端可以通过多种方式获取数据资源,比如监听指定文件、订阅 gRPC stream 以及轮询相应的 REST API 等。
在 Istio 架构中,基于 xDS 协议提供了标准的控制面规范,并以此向数据面传递服务信息和治理规则。在 Envoy 中,xDS 被称为数据平面 API,并且担任控制平面 Pilot 和数据平面 Envoy 的通信协议,同时这些 API 在特定场景里也可以被其他代理所使用。
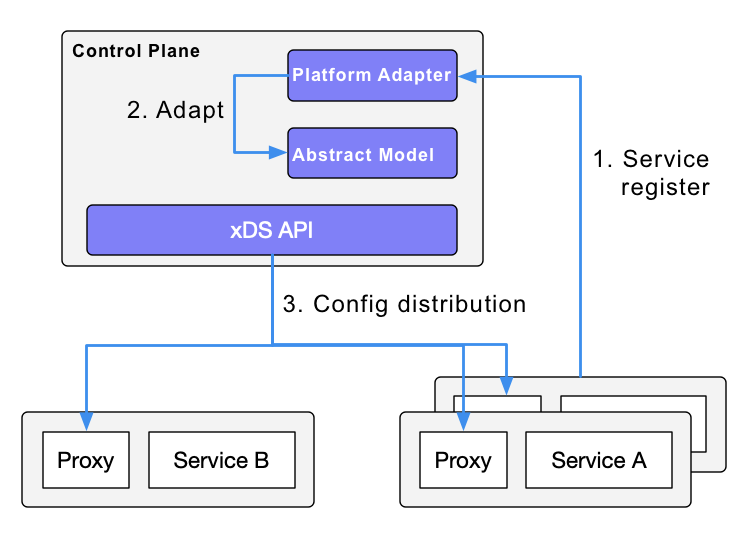
当前 istio 下发 xDS 使用的是全量下发策略,也就是网格里的所有 Sidecar,内存里都会有整个网格内所有的服务发现数据。通过分析社区全量下发的方案,发现在规模化的场景中,往往会出现瓶颈问题。主要体现在 xDS 的全量推送和频繁低效变更。
xDS 全量下发的模式通常会带来以下几个问题:
- 每个运行态的 sidecar 上面的 xDS 数据超大,而这些数据对当前 pod 来说绝大部分都是脏数据,这一来会影响 envoy 处理流量的耗时,二来也会消耗 envoy 很大的内存。
- 这种超大的 xDS 配置对于 istiod 更新 xDS 有很大的冲击,特别是 pod 数量成千上万的时候,这种数据更新就会变得很不及时,而这种不及时会导致这段时间内的流量有可能会出错。
- 排障困难,一个配置文件包含几十万条配置,排障起来十分困难。
因此设计 xDS 按需下发的方案,即下发的 xDS 数据一定是 Sidecar 所需要的,避免非必要的冗余数据和无效变更,提升服务网格的整体性能,满足规模化落地场景的需要。这里的按需下发主要是要收集微服务调用的依赖关系,会通过手动和程序自动收集的方式来收集。
参考
- Pattern: Service Mesh
- 什么是 Service Mesh
- The Future of Service Mesh is Networking
- Microservices in a Post-Kubernetes Era
- microservices
- eBPF and Wasm: Exploring the Future of the Service Mesh Data Plane
- eBPF 和 Wasm:探索服务网格数据平面的未来
- How eBPF will solve Service Mesh – Goodbye Sidecars
- 目前社区关于ServiceMesh的主要方向
- xDS
- 浅谈Service Mesh体系中的Envoy
- 大规模服务网格性能优化 | Aeraki xDS 按需加载
- Understanding the Sidecar Injection, Traffic Intercepting & Routing Process in Istio
- How to write WASM filters for Envoy and deploy it with Istio
- Accelerate Cloud Native with FD.io
公众号:Flowlet

「如果这篇文章对你有用,请随意打赏」
 ZhangShuai's Blog
ZhangShuai's Blog
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付

comments powered by Disqus