关于作者
张帅,网络从业人员,公众号:Flowlet
个人博客:https://flowlet.net/
云数据中心正在经历巨大的变革,虚拟化在经历了一虚多技术(一台 BM 虚拟成多台 VM )多年的发展后,正朝着多虚一技术(多台 BM 的多台 VM 虚拟成一台 VM )的方向进行演进。
在 60s 大型机时代,IBM 创始人老沃森,曾说过一句话:“世界只需要5台计算机”,随着云计算的兴起,虚拟化多虚一技术的发展,在 HPC 与 AI 应用场景的推动下,“世界只需要5台计算机” 即将成为现实。
虚拟化是实现云计算的核心技术之一,虚拟化的实现主要由三项关键技术构成:CPU虚拟化、内存虚拟化和I/O虚拟化。
I/O 虚拟化最关键的技术就是 Virtio,Virtio 来源于《Virtio: Towards a De-Facto Standard For Virtual I/O Devices》 这篇论文,该论文发表于2008年,10多年过去了 Virtio 已经发展成为 I/O 虚拟化的事实标准。
前言
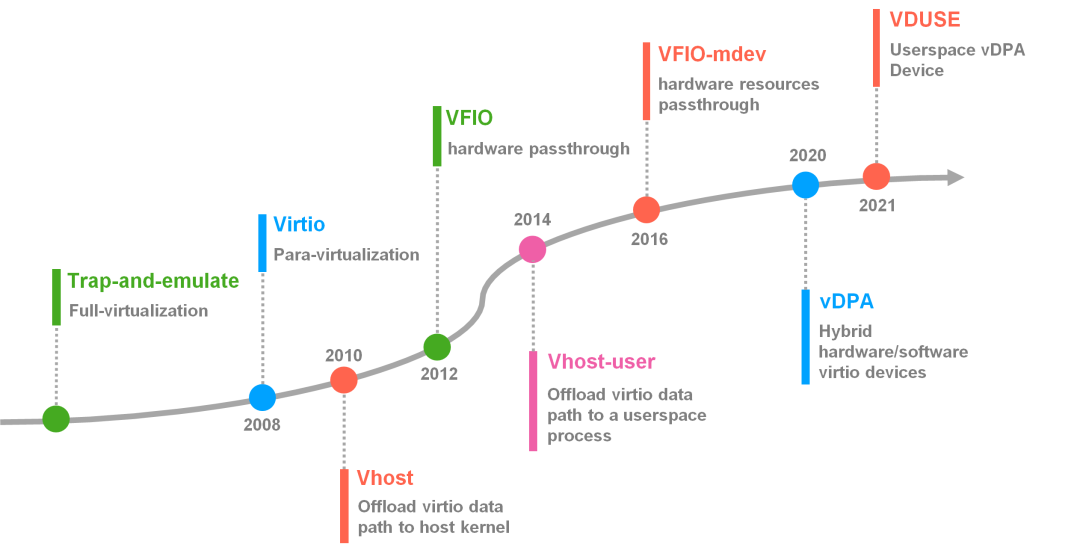
I/O 虚拟化经历了从 I/O 全虚拟化、I/O 半虚拟化、硬件直通再到 vDPA 加速 Vhost-user 技术的演进。
虚拟化架构的发展,将会催生新的网络架构的发展,本文将带大家了解 I/O 虚拟化技术:Virtio 与 Vhost-net 架构,由于笔者水平有限,文中不免有错误之处,欢迎指正交流。
1. Virtio 与 Vhost 协议介绍
Virtio 目前被用作虚拟机(VM)访问块设备(virtio-blk)和网络设备(virtio-net)的标准开放接口。Virtio-net 作为一种虚拟网卡,是 virtio 迄今为止支持的最复杂的设备。
1.1 Virtio 是如何被构建出来的?
Host 通过 hypervisor 运行 VM,每个 VM 都有独立的操作系统,Host 为 VM 提供虚拟 NIC,VM 可以像使用真正的 NIC 那样使用虚拟 NIC。
构建 Virtio 需要以下组件:
-
KVM - Kernel-based Virtual Machine(基于内核的虚拟机),它是一个 Linux 的一个内核模块,该内核模块使得 Linux 变成了一个 Hypervisor。因此 Host 可以运行多个彼此隔离的 Guest 虚拟机环境。Linux 内核提供作为一个 hypervisor 应该具有的诸如:内存管理、进程调度、网络协议栈等能力,这些 VM 在 Host 看来只不过是由标准 Linux 调度器调度的常规 Linux 进程。
-
QEMU - Host 上的 VMM(virtual machine monitor),为 guest 模拟各种不同的硬件设备。QEMU 可以与 KVM 一起使用,利用 KVM 提供的硬件辅助虚拟化技术以接近原生的速度运行 VM。QEMU 可以通过 QEMU Cli 运行 Guest,并可以通过 QEMU Cli 配置 Guest 所有必要功能。
-
Libvirt - 将前端 XML 配置转换为 QEMU Cli 配置,它同时提供了一个管理守护进程用于配置和管理 QEMU。例如,当 Openstack Nova 启动一台 VM 的同时,也通过 Libvirt 为该 VM 启动一个 QEMU 进程。
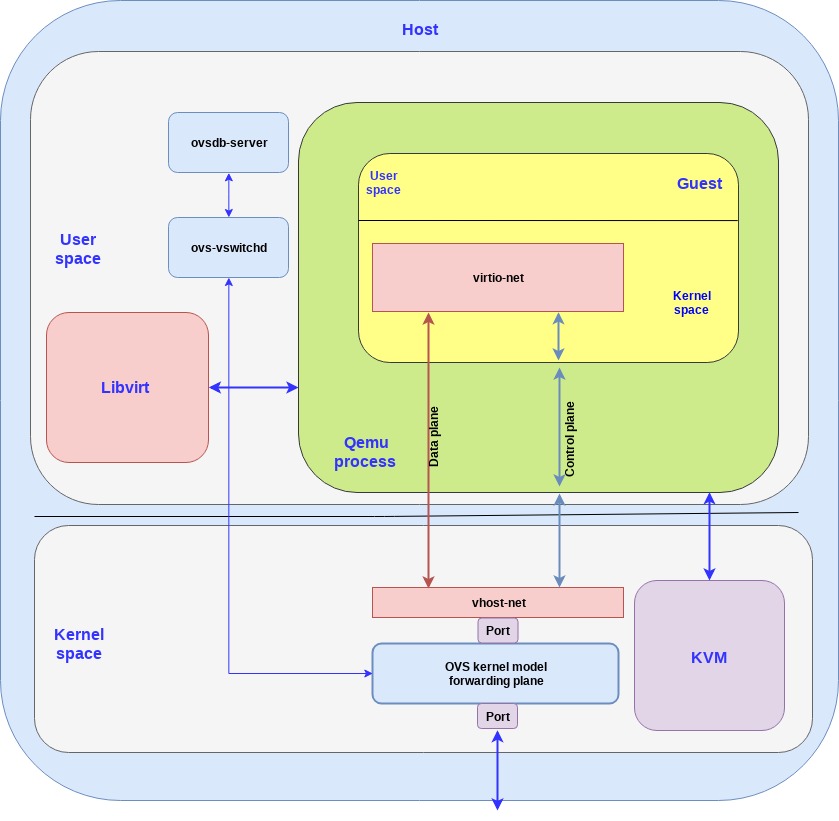
下图展示了这三个组件是如何组合在一起的:
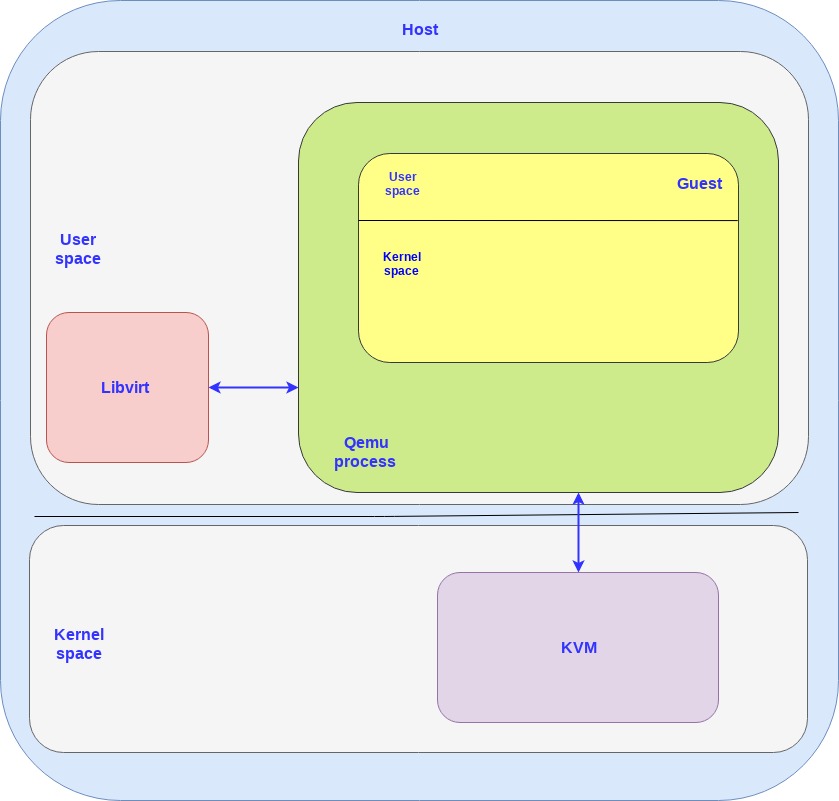
Host 与 Guest 都包含内核态与用户态,KVM 运行在 Host 的内核态,Libvirt 运行在 Host 的用户态。
Guest VM 运行在 QEMU 进程中,该进程只是 Host 在用户态运行的一个普通应用进程,Guest 可与 Libvirt(Host 用户态应用程序)和 KVM(Host 内核)进行通信。
每创建一个 VM 都会创建一个对应的 QEMU 进程,如果你创建 N 个 VM,则会同时创建 N 个 QEMU 进程,Libvirt 会跟每个 QEMU 进程进行通信。
1.2 Virtio 规范和 Vhost 协议
我们可以将 Vritio-net 分为两个平面:
-
控制面 - 用于在 Host 与 Guest 之间进行能力协商,同时用于建立和终止数据面。
-
数据面 - 用于 Host 与 Guset 之间传输数据包。
数据面需要尽可能快的转发数据包,控制面则需要做到尽可能的灵活,以便在未来的架构中支持不同的设备和厂商。
Guest 通过 Virtio 接口访问 Host 上的设备,我们可以将 Vritio 分为两个部分:
- virtio 规范 - virtio 规范由 OASIS(Organization for the Advancement of Structured Information Standards)组织维护,定义了如何在 Guest 与 Host 之间建立控制面与数据面。例如,该规范中详细描述了数据面 ring buffer 的构成。
- vhost 协议 - 允许将 virtio 数据面实现 offload 到用户态或内核中以增强性能。
Vhost 协议在 QEMU 进程中基于 virtio 规范实现了 virtio 的控制面,但并没有在 QEMU 进程中实现其数据面。之所以没有在 QEMU 进程中基于 virtio 规范同时实现 virtio 的数据面,是因为如果我们在 QEMU 进程中实现了 virtio 数据面,那么每当有数据包从 Host 发往 Guest 时就会发生一次上下文切换。反之亦然。这样会造成较大的性能开销,并且会增加转发时延。
Vhost 协议能够 bypass 掉 QEMU 进程,让数据包从 Host 直接转发到 Guest。Vhost 协议本身只是描述了如何建立数据面,具体的数据面的实现还需要按照 Virtio 规范中所描述的那样。
Vhost 协议可以在内核态(vhost-net)或者用户态(vhost-user)中实现, 本文主要描述 virtio 数据面在内核中的实现方式,也被称为 vhost-net 架构。
1.3 Vhost-net/Virtio-net 架构
virtio 接口有一个前端组件和一个后端组件:
-
前端组件是 virtio 接口的 guest 端。
-
后端组件是 virtio 接口的 host 端。
在 vhost-net/virtio-net 架构中组件如下所示:
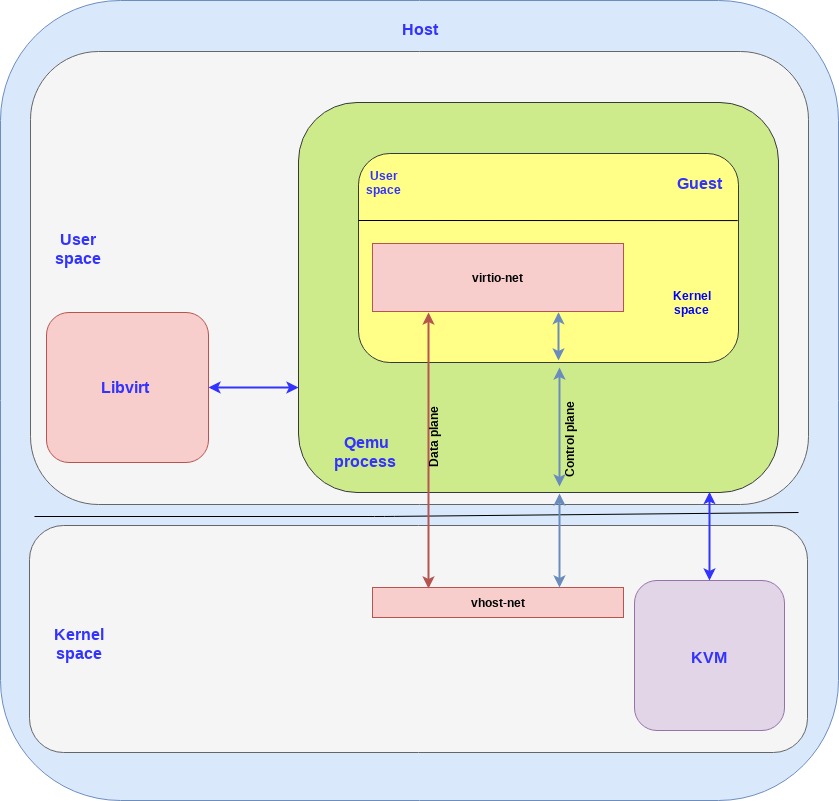
-
virtio-net 是前端组件,运行在 guest 的内核空间。
-
vhost-net 是后端组件,运行在 host 的内核空间。
需要注意几点:
-
vhost-net 与 virtio-net 均运行在 host 与 guest 的内核空间,因此我们有时也称其为 vhost-net/virtio-net 驱动。
-
我们在前端和后端之间拥有独立的控制面和数据面。vhost-net 使用 vhost 协议为数据面建立转发框架,该转发框架通过共享内存在 host 与 guest 之间转发数据包。
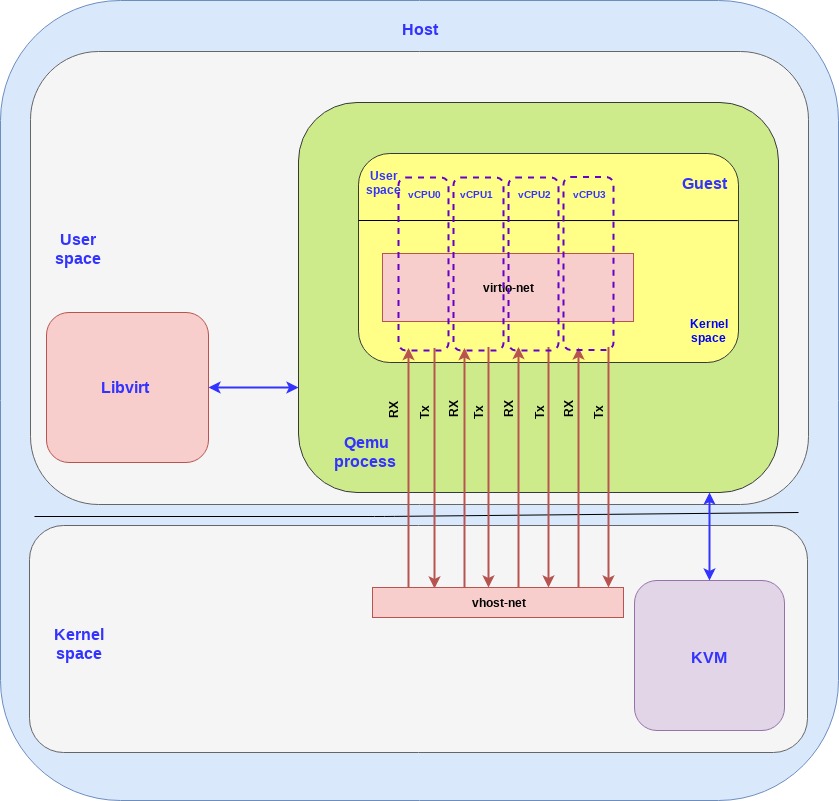
对于每个 guest 我们可以分配一些 vCPU ,基于每个 vCPU 我们创建 RX/TX 队列。下图我们以4个 vCPU 为例(为了简单起见移除了控制面):
1.4 Virtio 与 OVS
到目前为止,我们已经描述了 Guest 如何使用 virtio 接口将数据包传递到 Host 内核。我们使用 OVS 以便将这些数据包能够转发给在同一台 Host 上运行的 Guest 或 Host 外部(例如互联网)。
OVS 是一种软件交换机,可在内核中进行数据包转发。它由用户态部分和内核部分组成:
-
用户态部分 - 由用于管理和控制交换机的 OVS 守护进程(ovs-vswitchd)和 ovsdb-server 数据库组成。
-
内核态部分 - 由负责数据路径转发的 ovs kernel 模块组成。
OVS 控制器与 ovsdb-server 和内核转发面进行通信。在我们的例子中,我们用一个 port 把 OVS 内核转发面连接到物理网卡,而另一个 port 将 OVS 内核转发面连接到 vhost-net 后端。在实际应用中将会有多个物理网卡通过多个 port 连接到 OVS,同时还有多个虚拟机运行,因此将会有多个 port 将 OVS 连接到多个 vhost-net 后端。
下图展示了如何通过 OVS 连接到 virtio:
2. 深入理解 Virtio 与 vhost-net
本章,我们将带您深入理解 Virtio 与 vhost-net架构。
2.1 背景知识
2.1.1 TUN/TAP
TUN/TAP设备为用户空间的进程提供了相互转发数据包的能力。它可以被看作是一个简单的点对点设备,它不是从物理网卡接收数据包,而是从用户进程接收数据包,TUN/TAP设备将数据包写入到用户空间进程,而不是发送到物理网卡。
换句话说,TUN/TAP驱动程序在 Linux 主机上构建一个虚拟网络接口。该接口可以像任何其他网络接口一样,即可以给它分配IP,也可以将流量路由到该接口。当流量被发送到该接口时,流量将被发送到用户空间进程中,而不是真实的网络。
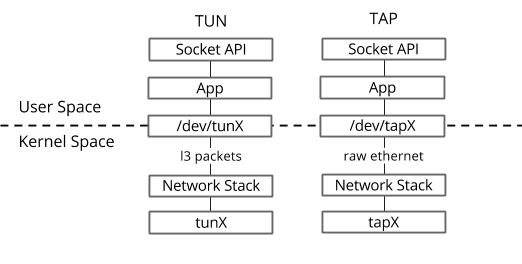
TUN/TAP 有两种驱动模式:
-
TUN(tunnel)设备工作在 IP 层,这意味着您将从文件描述符接收到 IP 数据包。写回设备的数据也必须封装成 IP 报文的形式。
-
TAP(network tap)设备的操作很像 TUN 设备,但是 TAP 设备工作在 L2 层,因此 TAP 设备可以接收和发送原始的以太报文。
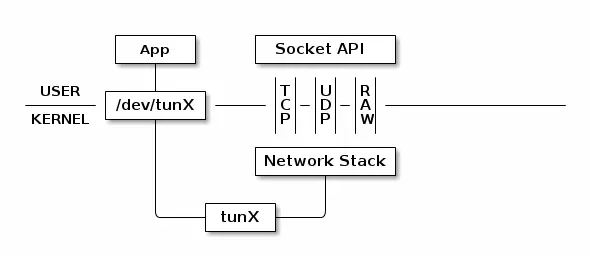
当 TUN/TAP 内核模块被加载时,它会创建一个特殊的设备/dev/net/tun。用户进程可以创建一个 tap 设备,打开该设备并向它发送特定的 ioctl 命令。新的 tap 设备在文件系统中有一个名称,另一个用户进程可以打开它,并通过它发送和接收数据包。
2.1.2 IPC
Unix 套接字:是在同一台机器上高效地进行进程间通信(IPC)的一种方式。在本文中,Server 将 Unix 套接字绑定到文件系统路径中,Client 使用该路径连接到它。
Eventfd:是 Linux 内核提供的一种轻量级的 IPC 方式。虽然 Unix 套接字允许发送和接收任何类型的数据,但 eventfd 通过一个进程间共享的64位计数器完成进程间通信。这个计数器由在 linux 内核空间维护,用户可以通过调用 write 方法向内核空间写入一个64位的值,也可以调用read方法读取这个值。这使得它们更适合作为等待/通知机制。
这两种 IPC 方式都为通信中的每个进程暴露一个文件描述符。fcntl 调用该文件描述符执行不同的操作,例如使它们成为非阻塞的(如果没有要读取的内容,则读取操作立即返回)。
共享内存:将多个进程的内存区域指向相同的内存页,一个/多个进程对该内存区域进行写入操作,另外一个/多个进程对该内存区域进行读取操作。
2.1.3 QEMU 与设备仿真
QEMU 是一个开源的计算机虚拟器和仿真器,几乎可以模拟任何硬件设备。QEMU 为 Guest 模拟一组不同的硬件和设备。对于 Host来说,QEMU 只是标准 Linux 调度器调度的常规进程。在该进程中,QEMU 为 Guest 分配内存地址(Guest 认为是物理地址),并执行 Guest 的 CPU 指令。
为了在裸金属服务器上执行 I/O 操作, CPU 必须与物理设备交互并执行特殊指令,并访问特定的内存区域,例如设备映射的内存区域。
当 Guest 访问这些内存区域时,控制权将交给QEMU, QEMU将以透明的方式为 Quest 执行设备模拟。
2.1.4 KVM
KVM 是内置在 Linux 中的开源虚拟化技术。它为虚拟化软件提供硬件辅助,使用内置的 CPU 虚拟化技术来减少虚拟化开销并提高安全性。
使用 KVM, QEMU 可以创建一个虚拟机,该虚拟机具有处理器能够识别的 vcpu,该 vcpu 运行原生指令。当 KVM 收到一个特殊的指令时,比如那些与设备交互的指令或到特殊内存区域的指令,vCPU 将会 pause 并通知 QEMU pause的原因,允许 hypervisor 对该事件做出反应。
在常规的 KVM 操作中,hypervisor 打开 /dev/kvm 设备,并使用 ioctl 调用创建VM、添加 CPU、添加内存(由 QEMU 分配,但从虚拟机的视角来看是物理的)、触发 CPU 中断(类似外部设备那样)等。例如,其中一个 ioctl 运行实际的 KVM vCPU,阻塞 QEMU 并使 vCPU 运行,直到它发现运行的指令需要硬件支持。此时,ioctl 返回(这称为vmexit), 与此同时 QEMU 获得退出的原因(例如,出错的指令)。
对于特殊的内存区域,KVM 遵循类似的方法,将内存区域标记为只读或根本不映射它们,此时 vmexit 并携带 KVM_EXIT_MMIO 的退出原因。
2.2 Virtio 规范
2.2.1 Virtio 设备与驱动规范
Virtio是 VM 实现 I/O 通信的标准规范,为虚拟设备提供了一套标准、简单、高效、可扩展的方案。
Virtio 规范基于两个元素:设备和驱动程序。hypervisor 向 Guest 暴露 virtio 设备。对于 Guest 来说,virtio 设备看起来像物理设备。
暴露 virtio 设备的典型(也是最简单的)方法是通过 PCI 接口,因为 PCI 协议在 QEMU 和 Linux 驱动程序中非常成熟。真正的 PCI 硬件的配置空间可以使用特定范围的物理内存地址(即,驱动程序可以通过访问该范围内的内存地址来进行读取或写入设备寄存器的操作)或特定的处理器指令来进行配置。
在 VM 环境中,hypervisor 暴露与真实机器相同的 PCI 空间地址,并捕获对该内存范围的访问。然后执行设备模拟,并提供相同的响应。virtio 规范还定义了其 PCI Configuration 空间布局规范。
当 Guest 启动并使用 PCI/PCIe 自动发现机制时,virtio设备使用 PCI vendor ID 和 PCI device ID 来标识自己。Guest 内核使用这些标识符来知道哪个驱动程序来处理该设备的请求(linux内核已经包含了 virtio 驱动程序)。
virtio 驱动程序必须能够分配内存,hypervisor 和 device 都可以通过共享内存的方式访问这些内存区域进行读写。控制面初始化这些内存区域,数据面使用这些内存区域进行数据通信。
内核提供一个通用的 virtio-pci 驱动程序,供实际的 Virtio 传输设备(例如 virtio-net 或 virtio-scsi)使用。
2.2.2 Virtqueues 规范
virtqueue 是在 virtio 设备上进行批量数据传输的实现机制。每个设备可以有零个或多个 virtqueue。它由 Guest 分配的缓冲区队列组成,Host 通过读取或写入缓冲区与之交互。此外,virtio 规范还定义了双向通信通知:
- 缓冲区可用通知:驱动程序使用该通知,表示有缓冲区数据已经准备好了,可以交由设备来进行处理。
- 缓冲区已用通知:设备使用该通知,表示它已完成了某些缓冲区的处理。
在使用 PCI 的情况下,Guest 通过向特定的内存地址写入内容,来发送可用缓冲区通知,而设备(在本例中为 QEMU )使用 vCPU 中断来发送已完成了某些缓冲区的处理。
virtio 规范还允许动态地启用或禁用通知。这样,设备和驱动程序在高吞吐的场景下可以主动轮询 virtqueue 中的新缓冲区进行批处理操作。
virtio 驱动接口暴露以下内容:
- 设备的 feature bits(设备和 Host 需要协商)
- Status bits
- 配置空间(包含设备特定的信息,如 MAC 地址)
- 通知系统(配置更改,缓冲区可用,缓冲区已使用)
- 零或多个 virtqueue
- 设备的特定传输接口
2.3 Virtio 网络 :qemu 实现方式
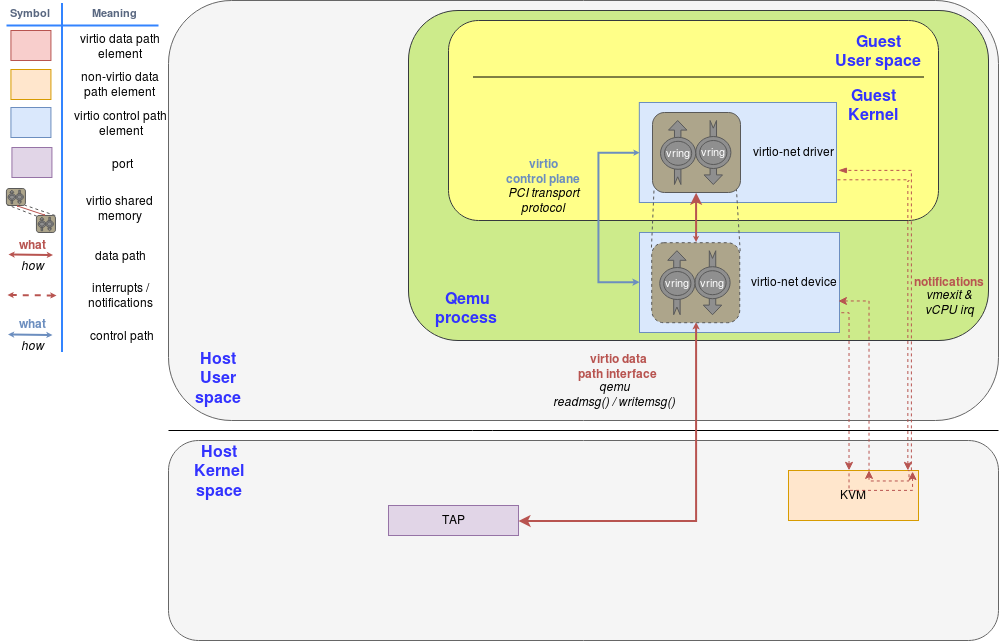
virtio 网络设备是一个虚拟网卡,TX/RX 支持多队列。在缓冲区中创建 N 个 virtqueue 用于接收数据包,另外 N 个 virtqueue 用于发送数据包。此外再创建一个 virtqueue 用于与数据面之外的驱动程序进行设备通信,比如用来设置高级过滤功能、设置 mac 地址或活动队列数量。支持 Virtio 的物理网卡支持许多 offload 特性,并且可以让 Host 上的设备执行这些操作。
发包时:驱动程序向设备发送一个缓冲区,其中包括元数据信息(例如期望 offload 该数据包),数据包被发送。驱动程序还可以将缓冲区分割成多个 entry 的集合,例如,它可以从数据包中分割元数据报头。
这些缓冲区由驱动程序管理,并由设备映射。本例中,设备位于 hypervisor “内部”。由于hypervisor(QEMU)可以访问所有 Guest 内存,因此能够定位缓冲区并读写它们。
下图显示了 virtio-net 设备使用 virtio-net 驱动程序进行配置和发送数据包的过程,该驱动程序通过 PCI 与 virtio-net 设备通信。在填充要发送的数据包后,它触发一个“可用缓冲区通知”,将控制权返回给QEMU,以便它可以通过 TAP 设备发送数据包。
然后 QEMU 将数据放入 virtqueue 并发送缓冲区已经使用的通知,通知 Guest 缓冲区操作(读或写)已经完成,从而触发 Guest 中 vCPU 中断。
收包过程与发包过程类似。唯一的区别是,在发包的场景下,空缓冲区是由客户机预先分配的,并可供设备使用,以便将传入的数据写入缓冲区。
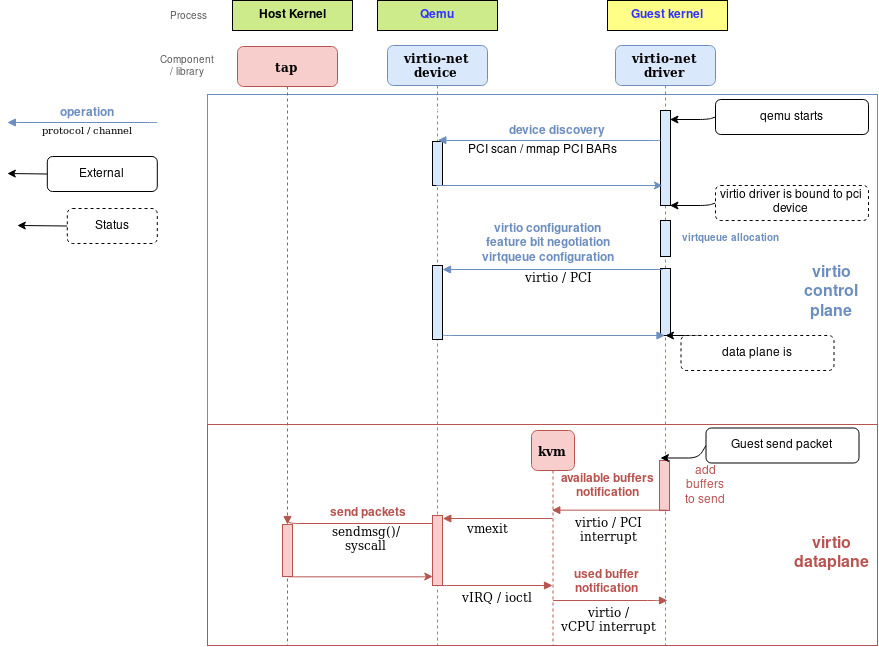
2.4 Vhost 协议
2.4.1 介绍
上面的实现 virtio 的方式有以下几个比较低效方面:
- 在 virtio 驱动程序发送一个缓冲区可用通知之后,vCPU 停止运行,控制权返回到 hypervisor,导致上下文切换。
- QEMU 额外的任务/线程同步机制。
- 通过 tap 口发送或接收数据包会导致系统调用和数据包的每包拷贝。
- vCPU 中断通过 ioctl 发送缓冲区可用通知。
- 还需要添加额外的系统调用来恢复vCPU的执行,以及所有相关映射的切换等。
vhost 协议被设计出来以用于解决这些缺陷。vhost API 是一种基于消息的协议,它允许 hypervisor 将数据面卸载给另一个组件(处理程序),以更有效地执行数据转发。使用此协议,Host 向处理程序发送以下配置信息:
- hypervisor 的内存布局。这样,处理程序就可以在 hypervisor 的内存空间中定位 virtqueue 和缓冲区。
- 一对文件描述符,用于程序处理 virtio 规范中定义的发送和接收通知。这些文件描述符在处理程序和 KVM 之间共享,因此它们可以直接通信,而不需要 hypervisor 的干预。
在此之后,hypervisor 将不再处理数据包(从 virtqueue 读取或写入)。相反,数据面处理将完全卸载到处理程序,处理程序现在可以直接访问 virtqueue 的内存区域,并直接向 Guest 发送和接收通知。
vhost 消息可以在任何 host-local 传输协议中进行传输,例如 Unix 套接字或字符设备,hypervisor 可以充当 server 或 client(在通信通道上下文中)。hypervisor 是协议的管理者,offload 设备是处理程序。
以下将介绍 vhost 协议基于内核实现的细节:vhost-net 内核驱动程序。
2.4.2 Vhost-net
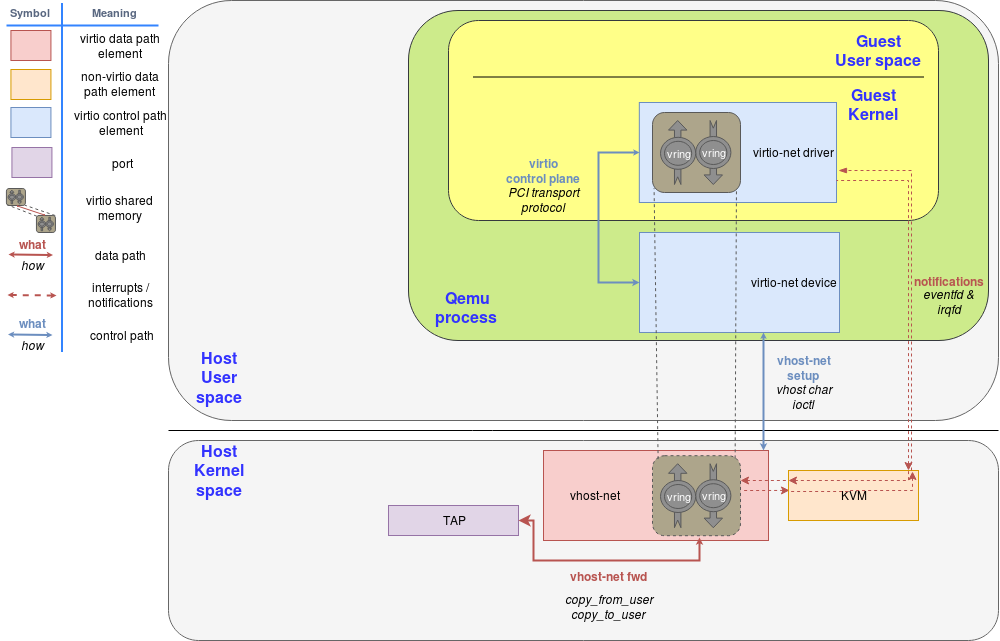
vhost-net 是一个内核驱动程序,是一个高效的数据转发平面。在这个实现中,qemu 和 vhost-net 内核驱动程序使用 ioctl 来交换 vhost 消息,使用两个类似事件 fd 的文件描述符 irqfd 和 ioeventfd 来与 Guest 程序交换通知消息。
当 vhost-net 内核驱动程序加载时,它会注册一个名为 /dev/vhost-net 的字符设备。当 qemu 在 vhost-net 支持下启动时,它会打开这个字符设备并通过 ioctl 调用初始化 vhost-net 实例,为 virtio 特性协商做准备以及将 Host 物理内存映射传递给 vhost-net 驱动程序。这些都是将 hypervisor 进程与 vhost-net 实例关联所必需的。
在初始化过程中,vhost-net 内核驱动程序创建了一个名为 vhost-$pid 的内核线程,其中 $pid 是 Guest 的进程 pid。这个线程称为 “vhost work 线程”。
tap 设备仍然用于 Guest 与 Host 通信,但现在工作线程处理 I/O 事件,它轮询驱动通知消息或 tap 事件,并转发数据。
Qemu 分配一个 eventfd 并将其注册到 vhost 和 KVM,以实现通知 bypass。vhost-$pid 内核线程轮询它,当客户机写特定地址时,KVM会写入它。这个机制被命名为ioeventfd。这样,对特定 Guest 内存地址的简单读/写操作就不需要经过昂贵的 QEMU 进程唤醒,并且可以直接路由到 vhost 工作线程。这个异步操作,不需要 vCPU 停止(因此不需要进行上下文切换)。
另一方面,qemu 分配另一个 eventfd,并再次将其注册到 KVM 和 vhost,用来直接注入 vCPU 中断。这种机制被称为 irqfd,它允许 Host 中的任何进程通过向 irqfd 写入值,来将vCPU中断注入到 Guest,这种机制具有相同的优点(异步,不需要进行上下文切换等)。
注意,virtio 包处理后端的这些更改对于仍然使用标准 virtio 接口的 Guest 来说是完全透明的。
下面的框图显示了从 QEMU 卸载到 vhost-net 内核驱动程序的数据路径:
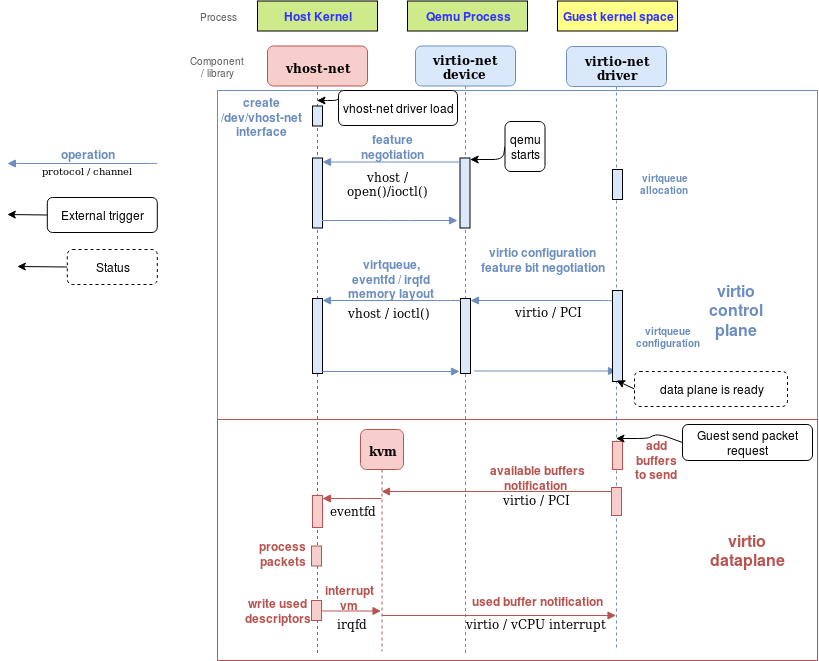
2.5 如何与外面的网络进行通信
Guest 可以使用 tap 设备与 Host 进行通信,但问题是它如何与同一 Host 上的其他 vm 或 Host 之外的机器通信(例如:internet)。
我们可以通过使用内核网络协议栈提供的任何转发或路由机制来实现这一点,比如标准的 Linux 网桥。然而,更高级的解决方案是使用开源虚拟交换机(OVS)。
正如概述帖子中所述,OVS数据路径在此场景中作为内核模块运行,OVS-vswitchd 作为用户态控件组件管理守护进程,ovsdb-server 作为转发数据库。
如下图所示,内核中运行着 OVS 数据面,在物理网卡和虚拟 TAP 设备之间转发报文:
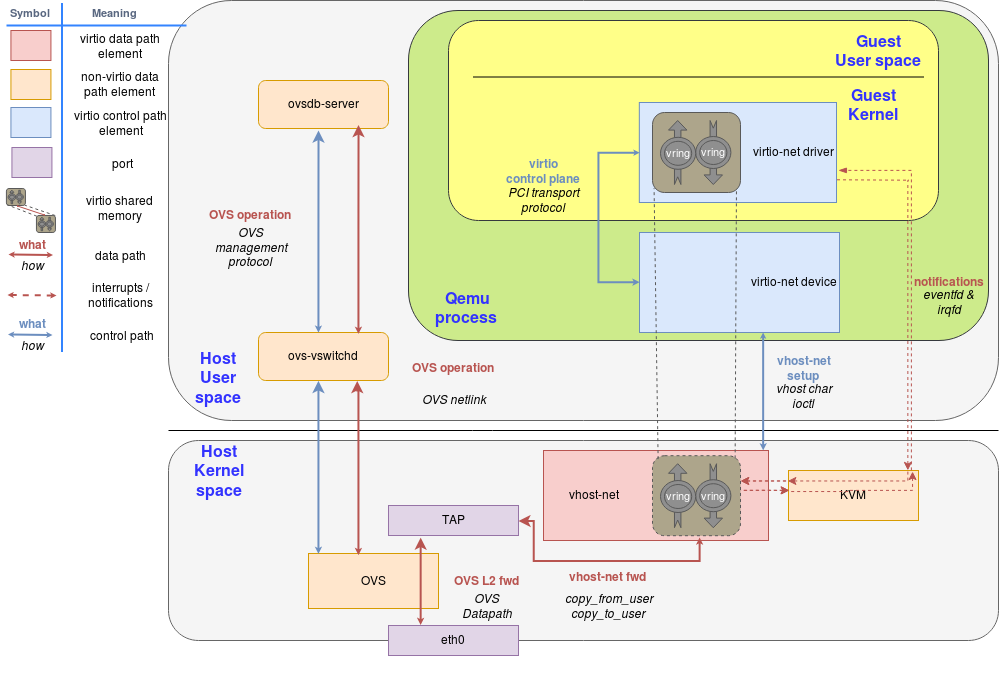
当同一台 Host 环境上的多台 VM 时,每台 VM 都有其一个对应的 QEMU 进程、TAP口和 vhost-net 驱动程序,这有助于避免 QEMU 上下文切换。
3. Vhost-net 实践
3.1 准备
3.1.1 VMware® Workstation 开启嵌套虚拟化
由于笔者通过 Windows10 PC 进行 Vhost-net 实验。
通过 Windows10 PC 安装 VMware® Workstation 17 Pro 软件,VMware® Workstation 运行 Ubuntu 20.04.5 LTS 虚拟机,然后基于这个 Ubuntu 20.04.5 LTS 虚拟机开启 KVM 虚拟化,再运行 Ubuntu 20.04.5 LTS 虚拟机,简单的说就是虚拟机里运行虚拟机。
最终实验环境构建如下:
Windows10 + VMware® Workstation 17 Pro + Ubuntu 20.04.5 LTS + Ubuntu 20.04.5 LTS
-
VMware® Workstation 启动 Ubuntu 20.04.5 LTS 虚拟机的时候勾选:Intel VT-x/EPT或AMD-V/RVI(V)
-
Ubuntu 虚拟机启动后查看是否支持硬件虚拟化,KVM 是半虚拟化技术需要依赖 CPU 硬件虚拟化技术
egrep -c '(vmx|svm)' /proc/cpuinfo
输出的结果大于0,则表示支持 KVM 虚拟化。
3.1.2 安装需要的软件包
- 安装必要的软件包
apt install -y qemu-kvm libvirt-daemon-system
- libvirt-daemon-system :包含libvirt(管理虚拟机和其他虚拟化功能(比如存储管理,网络管理))的软件集合。它包括一个API库,一个守护程序(libvirtd)和一个命令行工具(virsh)。
- qemu-kvm:实现KVM虚拟化的主要软件包。
安装好后,通过 kvm-ok 命令查看是否可以创建 KVM 虚拟机:
root@ubuntu:/home/ubuntu/vhost-net# kvm-ok
INFO: /dev/kvm exists
KVM acceleration can be used
- 下载 ubuntu cloud image
首先需要确定所使用的 Ubuntu 版本,然后从官方镜像列表中下载相应的cloud image。cloud image 预装了 cloud-init,可以更方便地运行在 openstack 等云平台中。
Cloud-init 是行业标准的跨平台云实例初始化的方法。能够对新创建的云服务器中指定的自定义信息(主机名、密钥和用户数据等)进行初始化配置。主要的公共云厂商、私有云厂商的和裸金属安装方案都支持Cloud-init。cloud-init 大幅简化了云主机的复杂配置过程,只需要编写一个统一的配置文件,就可以在不同的云平台创建出相同规格的主机实例。
cd /home/ubuntu/vhost-net
wget http://cloud-images.ubuntu.com/focal/current/focal-server-cloudimg-amd64.img
国内可以使用清华镜像站加速:
wget https://mirrors.tuna.tsinghua.edu.cn/ubuntu-cloud-images/focal/current/focal-server-cloudimg-amd64.img
3.2 创建 VM
3.2.1 制作模板镜像
基于初始镜像创建模板镜像,并命名为 vhost-net.qcow2:
qemu-img create -f qcow2 -b focal-server-cloudimg-amd64.img vhost-net.qcow2 20G
3.2.2 创建 VM 网络配置
root@ubuntu:/home/ubuntu/vhost-net# virsh net-define /etc/libvirt/qemu/networks/default.xml
Network default defined from /etc/libvirt/qemu/networks/default.xml
root@ubuntu:/home/ubuntu/vhost-net# virsh net-start default
Network default started
root@ubuntu:/home/ubuntu/vhost-net# virsh net-list
Name State Autostart Persistent
--------------------------------------------
default active yes yes
3.2.3 创建VM
- 安装 virt-install软件
apt install virtinst -y
- 创建 VM
network model 配置为:virtio
os-variant:指定操作系统类型,KVM 会根据设置做特定优化。可以通过 osinfo-query os 查看支持的 os 类型:
apt install libosinfo-bin -y
root@ubuntu:/home/ubuntu/vhost-net# osinfo-query os | grep ubuntu20.04
ubuntu20.04 | Ubuntu 20.04 | 20.04 | http://ubuntu.com/ubuntu/20.04
root@ubuntu:/home/ubuntu/vhost-net# virt-install --import --name vhost-net --ram=2048 --vcpus=1 --nographics --accelerate \
--network network:default,model=virtio --debug --wait 0 --console pty \
--disk /home/ubuntu/vhost-net/vhost-net.qcow2,bus=virtio --os-variant ubuntu20.04
root@ubuntu:/home/ubuntu/vhost-net# virsh list --all
Id Name State
---------------------------
1 vhost-net running
- 修改 VM 登录密码
由于我们安装的时候没有安装图形界面,所以未指定 VM 登录密码。通过 virt-edit 更改 root 用户密码:
apt install libguestfs-tools -y
root@ubuntu:/home/ubuntu/vhost-net# virsh shutdown vhost-net
root@ubuntu:/home/ubuntu/vhost-net# virt-edit -d vhost-net /etc/shadow
root:*:19403:0:99999:7::: 改为 root::19403:0:99999:7:::
默认配置为 root 用户不需要登录密码。
键入:ctrl + ],退出虚拟机
3.2.4 检查 VM
通过virsh dumpxml 查看 virtio 硬件相关的描述:
root@ubuntu:/home/ubuntu/vhost-net# virsh dumpxml
|
|
可以看到已经创建了 virtio设备,并为其分配了 BAR 地址空间:0000:05:00.0 登录 VM 查看通过 lspci 查看 virtio设备:
root@ubuntu:/home/ubuntu/vhost-net# virsh console vhost-net
root@ubuntu:~# lspci -s 0000:05:00.0
05:00.0 Unclassified device [00ff]: Red Hat, Inc. Virtio RNG (rev 01)
3.2.4 检查 Host
查看 vhost-net 驱动是否被加载:
root@ubuntu:/home/ubuntu/vhost-net# lsmod | grep vhost
vhost_net 32768 1
vhost 49152 1 vhost_net
tap 24576 1 vhost_net
查看 vhost-net 内核线程:
root@ubuntu:/home/ubuntu/vhost-net# ps -ef | grep vhost
root 3313 2 0 15:18 ? 00:00:00 [vhost-3308]
root@ubuntu:/home/ubuntu/vhost-net# ps -ef | grep 3308
libvirt+ 3308 1 99 15:18 ? 00:00:27 /usr/bin/qemu-system-x86_64 -name guest=vhost-net ...
查看 QEMU 进程分配给 tun、kvm、vhost-net 设备的文件描述符
root@ubuntu:/home/ubuntu/vhost-net# ls -lh /proc/$(pgrep qemu)/fd | grep '/dev'
lrwx------ 1 libvirt-qemu kvm 64 Apr 4 15:25 0 -> /dev/null
lrwx------ 1 libvirt-qemu kvm 64 Apr 4 15:25 10 -> /dev/ptmx
lrwx------ 1 libvirt-qemu kvm 64 Apr 4 15:25 12 -> /dev/kvm
lrwx------ 1 libvirt-qemu kvm 64 Apr 4 15:25 33 -> /dev/net/tun
lrwx------ 1 libvirt-qemu kvm 64 Apr 4 15:25 34 -> /dev/vhost-net
lr-x------ 1 libvirt-qemu kvm 64 Apr 4 15:25 9 -> /dev/urandom
查看 QEMU 进程创建的 tap 口:
root@ubuntu:/home/ubuntu/vhost-net# ip -d tuntap
virbr0-nic: tap persist
Attached to processes:
vnet0: tap vnet_hdr
Attached to processes:qemu-system-x86(3308)
查看 Guest 与 Host 连接的网桥:
apt install bridge-utils -y
root@ubuntu:/home/ubuntu/vhost-net# brctl show
bridge name bridge id STP enabled interfaces
virbr0 8000.5254002e07e8 yes virbr0-nic
vnet0
3.2.5 VM 网络配置
由于我们创建 VM 的时候指定网络配置为:–network network:default,model=virtio,则 VM 网络默认使用 NAT 模式。
root@ubuntu:/home/ubuntu/vhost-net# virt-install --import --name vhost-net --ram=2048 --vcpus=1 --nographics --accelerate \
--network network:default,model=virtio --debug --wait 0 --console pty \
--disk /home/ubuntu/vhost-net/vhost-net.qcow2,bus=virtio --os-variant ubuntu20.04
libvirt默认使用了一个名为 default 的 nat 网络,这个网络默认使用 virbr0 作为桥接接口,通过 dnsmasq 为使用 nat 网络的虚拟机提供 dns 及 dhcp 服务。
登录 Guest,查看ip地址:此时发现 enp1s0 接口没有分配 ip 地址。
root@ubuntu:/home/ubuntu/vhost-net# virsh console vhost-net
root@ubuntu:~# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp1s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:97:46:5c brd ff:ff:ff:ff:ff:ff
Ubuntu 20.04 通过 netplan 管理 网卡的 ip 地址分配,netplan 底层调用的还是 network-manager 来进行网络的管理。 查看虚拟机没有安装 network-manager 程序,先通过 dhclient 触发 dhcp request 获得接口 ip 地址:
|
|
|
|
Guest 安装 network-manager 后面通过 netplan 自动管理网络:
root@ubuntu:~# apt update
root@ubuntu:~# apt install network-manager -y
root@ubuntu:~# vim /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
enp1s0:
dhcp4: true
root@ubuntu:~# netplan apply
在 Host 中查看 dhcp 分配给虚拟机的 ip 地址,存放在 /var/lib/libvirt/dnsmasq/virbr0.status 文件中:
root@ubuntu:/home/ubuntu/vhost-net# cat /var/lib/libvirt/dnsmasq/virbr0.status
[
{
"ip-address": "192.168.122.13",
"mac-address": "52:54:00:97:46:5c",
"hostname": "ubuntu",
"client-id": "ff:56:50:4d:98:00:02:00:00:ab:11:27:2e:23:29:2b:b7:74:de",
"expiry-time": 1680626940
}
]
虚拟机启动的时候会动态生成 iptables nat 表与 filter 表,以实现 SNAT 功能,从而实现虚拟机访问外网。
root@ubuntu:/home/ubuntu/vhost-net# iptables -t nat -nL
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
DOCKER all -- 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 0.0.0.0/0
LIBVIRT_PRT all -- 0.0.0.0/0 0.0.0.0/0
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- 0.0.0.0/0 0.0.0.0/0
Chain LIBVIRT_PRT (1 references)
target prot opt source destination
RETURN all -- 192.168.122.0/24 224.0.0.0/24
RETURN all -- 192.168.122.0/24 255.255.255.255
MASQUERADE tcp -- 192.168.122.0/24 !192.168.122.0/24 masq ports: 1024-65535
MASQUERADE udp -- 192.168.122.0/24 !192.168.122.0/24 masq ports: 1024-65535
MASQUERADE all -- 192.168.122.0/24 !192.168.122.0/24
root@ubuntu:/home/ubuntu/vhost-net# iptables -t filter -nL
Chain INPUT (policy ACCEPT)
target prot opt source destination
LIBVIRT_INP all -- 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy ACCEPT)
target prot opt source destination
DOCKER-USER all -- 0.0.0.0/0 0.0.0.0/0
DOCKER-ISOLATION-STAGE-1 all -- 0.0.0.0/0 0.0.0.0/0
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
DOCKER all -- 0.0.0.0/0 0.0.0.0/0
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
LIBVIRT_FWX all -- 0.0.0.0/0 0.0.0.0/0
LIBVIRT_FWI all -- 0.0.0.0/0 0.0.0.0/0
LIBVIRT_FWO all -- 0.0.0.0/0 0.0.0.0/0
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
LIBVIRT_OUT all -- 0.0.0.0/0 0.0.0.0/0
Chain DOCKER (1 references)
target prot opt source destination
Chain DOCKER-ISOLATION-STAGE-1 (1 references)
target prot opt source destination
DOCKER-ISOLATION-STAGE-2 all -- 0.0.0.0/0 0.0.0.0/0
RETURN all -- 0.0.0.0/0 0.0.0.0/0
Chain DOCKER-ISOLATION-STAGE-2 (1 references)
target prot opt source destination
DROP all -- 0.0.0.0/0 0.0.0.0/0
RETURN all -- 0.0.0.0/0 0.0.0.0/0
Chain DOCKER-USER (1 references)
target prot opt source destination
RETURN all -- 0.0.0.0/0 0.0.0.0/0
Chain LIBVIRT_FWI (1 references)
target prot opt source destination
ACCEPT all -- 0.0.0.0/0 192.168.122.0/24 ctstate RELATED,ESTABLISHED
REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
Chain LIBVIRT_FWO (1 references)
target prot opt source destination
ACCEPT all -- 192.168.122.0/24 0.0.0.0/0
REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
Chain LIBVIRT_FWX (1 references)
target prot opt source destination
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
Chain LIBVIRT_INP (1 references)
target prot opt source destination
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:53
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:53
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:67
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:67
Chain LIBVIRT_OUT (1 references)
target prot opt source destination
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:53
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:53
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:68
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:68
登录 Guest 并测试网络流量是否能够访问外网:
查看路由:
|
|
ping 网关测试:
root@ubuntu:~# ping 192.168.122.1
PING 192.168.122.1 (192.168.122.1) 56(84) bytes of data.
64 bytes from 192.168.122.1: icmp_seq=1 ttl=64 time=0.570 ms
64 bytes from 192.168.122.1: icmp_seq=2 ttl=64 time=0.299 ms
64 bytes from 192.168.122.1: icmp_seq=3 ttl=64 time=0.462 ms
^C
--- 192.168.122.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2004ms
rtt min/avg/max/mdev = 0.299/0.443/0.570/0.111 ms
ping 外网测试:
root@ubuntu:~# ping baidu.com
PING baidu.com (39.156.66.10) 56(84) bytes of data.
64 bytes from 39.156.66.10 (39.156.66.10): icmp_seq=1 ttl=127 time=9.59 ms
64 bytes from 39.156.66.10 (39.156.66.10): icmp_seq=2 ttl=127 time=9.37 ms
^C
--- baidu.com ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 9.371/9.482/9.594/0.111 ms
在 Host 通过 top 查看各个线程的资源占用情况:可以看到qemu-system-x86进程与vhost-$pid 内核线程:
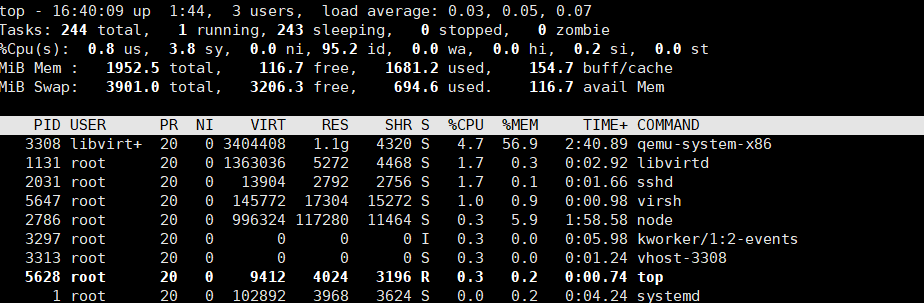
参考
- 本文理论部分参考自 Redhat 社区关于 Learn about virtio-networking 系列文章。如需了解更多,推荐阅读原文。
- 本文第三节部分,为笔者基于自己的 PC 所搭建的实验环境。
公众号:Flowlet

「如果这篇文章对你有用,请随意打赏」
 ZhangShuai's Blog
ZhangShuai's Blog
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付

comments powered by Disqus